Prezentare pe tema „Ziua Pământului”
Elena Shishkina Prezentare „Ziua Pământului” Prezentare „Ziua Pământului”. Scop: să formeze idei că planeta...
Termenul „analiză cluster” a fost folosit pentru prima dată de psihologul american Robert Tryon în lucrarea sa cu același nume încă din 1930. În ciuda acestui fapt, termenii „cluster” și „cluster analysis” sunt percepuți de vorbitorii nativi ca noi, după cum a remarcat Alexander Khrolenko, care a efectuat o analiză de corpus a utilizării lexemului „cluster”: „majoritatea autorilor care folosesc acest termen acordă atenție. la noutatea sa” (Khrolenko , 2016, p. 106)
Analiza cluster include mulți algoritmi de clasificare diferiți, al căror scop este de a organiza informațiile în clustere. Este important să ne amintim că analiza cluster nu este un algoritm specific în sine, ci o problemă care trebuie rezolvată. În lucrarea sa „The Scarcity of Linear Hierarchy”, Mark Ereshefsky notează că analiza cluster este unul dintre cele trei tipuri de clasificare a obiectelor din lumea înconjurătoare, împreună cu esențialismul și clasificarea istorică.
În lingvistică, principiul descriere a clusterului presupune, pe lângă analiza unităților incluse în acest cluster, și analiza relațiilor din cadrul acestora. Acestea pot fi conexiuni la diferite niveluri: de la logice (paradigmatice și sintagmatice, de exemplu) până la formarea cuvintelor și conexiuni fonetice.
F. Brown prezintă următorii pași analiza clusterului(Maro):
Trebuie remarcat faptul că al treilea punct ridică întrebări, deoarece trăsătura distinctivă a grupării ca metodă de clasificare este absența claselor specificate. Gruparea documentelor este o sarcină de regăsire a informațiilor. Spre deosebire de categorizarea textului, aceasta nu implică categorii predefinite sau un set de antrenament. Clusterele și relațiile dintre ele sunt „extrase automat din documente, iar documentele sunt atribuite succesiv acestor clustere” (Golub, pp. 52-53) Mark Ereshefsky introduce analiza clusterului ca metodă de clasificare. El consideră că „toate formele de analiză a clusterelor se bazează pe două ipoteze: membrii unui grup taxonomic trebuie să aibă un grup de trăsături în comun, iar acele trăsături nu pot apărea în toate sau doar într-un singur membru al acelui grup”. (Ereshefsky, p. 15)
În lucrarea sa „Cluster abordare în analiza lingvistică” (Nurgalieva, 2013) N.Kh. Nurgalieva identifică patru sarcini principale ale analizei cluster:
Toate metodele de analiză a clusterului pot fi împărțite în analiză cluster „hard”, clară, atunci când fiecare obiect fie aparține unui cluster sau nu, și în analiza cluster „soft”, neclară, când fiecare obiect aparține unui grup cu un anumit grad de probabilitate.
Metodele de analiză a clusterelor sunt, de asemenea, împărțite în ierarhice și non-ierarhice. Metodele ierarhice presupun prezența unor grupuri imbricate, spre deosebire de metodele neierarhice. Nurgalieva notează că metoda ierarhică „pare a fi cea mai potrivită pentru rezolvarea problemelor lingvistice” (Nurgalieva, p. 1), deoarece vă permite să vedeți și să analizați structura fenomenului studiat.
Studenții, studenții absolvenți, tinerii oameni de știință care folosesc baza de cunoștințe în studiile și munca lor vă vor fi foarte recunoscători.
Postat pe http://www.allbest.ru/
Introducere
1. Definirea și sarcinile analizei cluster
2. Metode de analiză a clusterelor
3. Dendograme
Concluzie
Referințe
Introducere
Analiza clusterelor este un set de metode care vă permit să clasificați observațiile multidimensionale. Termenul de analiză de cluster, introdus pentru prima dată de Tryon în 1939, include peste 100 de algoritmi diferiți.
Spre deosebire de problemele de clasificare, analiza cluster nu necesită ipoteze a priori despre setul de date, nu impune restricții privind reprezentarea obiectelor studiate și vă permite să analizați indicatorii diverse tipuri date (date de interval, frecvențe, date binare). Trebuie reținut că variabilele trebuie măsurate pe scale comparabile.
Analiza cluster vă permite să reduceți dimensiunea datelor și să le faceți mai clare.
Analiza cluster este utilizată pentru a identifica grupuri de puncte din date care sunt în mod clar diferite unele de altele. Importanța rezolvării acestei probleme se datorează faptului că utilizarea instrumentelor standard de analiză a datelor (inclusiv proceduri econometrice standard) în prezența clusterelor în date va duce la o schimbare atât a estimărilor punctuale (coeficienți de regresie), cât și a erorilor standard, şi deci la concluzii statistice incorecte. În plus, structura datelor și similitudinea observațiilor pot fi de interes independent.
Analiza clusterelor este concepută pentru a împărți un set de obiecte în grupuri omogene (clustere sau clase). În esență, aceasta este o problemă de clasificare a datelor multidimensionale.
1. Definirea și sarcinile analizei cluster
Atunci când analizează și prognozează fenomene socio-economice, cercetătorul întâlnește destul de des multidimensionalitatea descrierii acestora. Acest lucru se întâmplă atunci când se rezolvă problema segmentării pieței, se construiește o tipologie de țări bazată pe un număr suficient de mare de indicatori și se prognozează condițiile pieței. bunuri individuale, studiind și prognozând depresia economică și multe alte probleme.
Metodele de analiză multivariată reprezintă cel mai eficient instrument cantitativ pentru studierea proceselor socio-economice descrise de un număr mare de caracteristici. Acestea includ analiza clusterului, taxonomia, recunoașterea modelelor, analiza factorială.
Analiza cluster reflectă cel mai clar caracteristicile analizei multidimensionale în clasificare, analiza factorială - în studiul comunicării.
Uneori abordarea analizei cluster este denumită în literatură taxonomie numerică, clasificare numerică, recunoaștere prin auto-învățare etc.
Analiza cluster și-a găsit prima aplicație în sociologie. De la analiza clusterului de nume provine Cuvânt englezesc cluster - ciorchine, acumulare. Pentru prima dată în 1939, subiectul analizei cluster a fost definit și descris de cercetătorul Trion. Scopul principal al analizei cluster este de a împărți setul de obiecte și caracteristici studiate în grupuri sau clustere care sunt omogene în sensul corespunzător. Aceasta înseamnă că problema clasificării datelor și identificării structurii corespunzătoare din acestea este în curs de rezolvare. Metodele de analiză a clusterelor pot fi utilizate într-o mare varietate de cazuri, chiar și în cazurile în care vorbim de grupare simplă, în care totul se rezumă la formarea de grupuri pe baza similitudinii cantitative.
Marele avantaj al analizei cluster este că vă permite să divizați obiectele nu în funcție de un parametru, ci în funcție de un întreg set de caracteristici. În plus, analiza cluster, spre deosebire de majoritatea metodelor matematice și statistice, nu impune nicio restricție asupra tipului de obiecte luate în considerare și permite să se ia în considerare o varietate de date inițiale de natură aproape arbitrară. Are mare valoare, de exemplu, pentru prognoza situației pieței, când indicatorii au o formă diversă, ceea ce face dificilă utilizarea abordărilor econometrice tradiționale.
Analiza cluster vă permite să luați în considerare o cantitate destul de mare de informații și să reduceți și să comprimați dramatic cantități mari de informații socio-economice, făcându-le compacte și vizuale.
Analiza clusterelor este importantă în raport cu seturile de caracterizare a seriilor temporale dezvoltarea economică(de exemplu, condițiile generale economice și ale mărfurilor). Aici puteți evidenția perioadele în care valorile indicatorilor corespunzători au fost destul de apropiate și, de asemenea, puteți determina grupuri de serii temporale a căror dinamică este cel mai asemănătoare.
Analiza cluster poate fi utilizată iterativ. În acest caz, cercetarea se efectuează până la obținerea rezultatelor necesare. Mai mult, fiecare ciclu de aici poate oferi informații care pot schimba foarte mult direcția și abordările pentru aplicarea ulterioară a analizei cluster. Acest proces poate fi reprezentat ca un sistem de feedback.
În sarcinile de prognoză socio-economică, combinarea analizei cluster cu alte metode cantitative (de exemplu, analiza regresiei) este foarte promițătoare.
Ca orice altă metodă, analiza clusterului are anumite dezavantaje și limitări: în special, compoziția și numărul de clustere depind de criteriile de partiție selectate. La reducerea matricei de date originale la o formă mai compactă, pot apărea anumite distorsiuni, iar caracteristicile individuale ale obiectelor individuale se pot pierde din cauza înlocuirii lor cu caracteristicile valorilor generalizate ale parametrilor clusterului. La clasificarea obiectelor, posibilitatea absenței oricăror valori de grup în setul luat în considerare este foarte des ignorată.
În analiza clusterului se consideră că:
a) caracteristicile selectate permit, în principiu, împărțirea dorită în clustere;
b) unitățile de măsură (scara) sunt alese corect.
Alegerea scalei joacă un rol important. De obicei, datele sunt normalizate prin scăderea mediei și împărțirea la abaterea standard, astfel încât varianța să fie egală cu unu.
Sarcina analizei cluster este de a împărți, pe baza datelor conținute în mulțimea X, mulțimea de obiecte G în m (m este un întreg) clustere (subseturi) Q1, Q2, ..., Qm, astfel încât fiecare obiect Gj aparține unuia și numai unui subset al partiției și astfel încât obiectele aparținând aceluiași cluster sunt similare, în timp ce obiectele aparținând clusterelor diferite sunt eterogene.
De exemplu, să fie G să includă n țări, dintre care oricare este caracterizată prin PNB pe cap de locuitor (F1), numărul M de mașini la 1 mie de persoane (F2), consumul de energie electrică pe cap de locuitor (F3), consumul de oțel pe cap de locuitor (F4) , etc. Atunci X1 (vector de măsurare) este un set de caracteristici specificate pentru prima țară, X2 pentru a doua, X3 pentru a treia etc. Scopul este de a clasifica țările după nivelul de dezvoltare.
Soluția problemei analizei cluster sunt partițiile care îndeplinesc un anumit criteriu de optimitate. Acest criteriu poate fi un fel de funcțional care exprimă nivelurile de dezirabilitate ale diferitelor partiții și grupări, care se numește funcție obiectiv. De exemplu, suma din cadrul grupului a abaterilor pătrate poate fi luată ca funcție obiectiv:
unde xj reprezintă măsurătorile j-lea obiect.
Pentru a rezolva problema analizei cluster, este necesar să se definească conceptul de similaritate și eterogenitate.
Este clar că obiectele i-th și j-th ar cădea într-un grup atunci când distanța (depărtarea) dintre punctele Xi și Xj ar fi suficient de mică și ar cădea în grupuri diferite când această distanță ar fi suficient de mare. Astfel, căderea în unul sau mai multe grupuri de obiecte este determinată de conceptul distanței dintre Xi și Xj față de Ep, unde Ep este un spațiu euclidian p-dimensional. O funcție nenegativă d(Xi, Xj) se numește funcție de distanță (metrică) dacă:
a) d(Хi, Хj) і 0, pentru toate Хi și Хj din Ep
b) d(Хi, Хj) = 0, dacă și numai dacă Хi = Хj
c) d(Хi, Хj) = d(Хj, Хi)
d) d(Хi, Хj) Ј d(Хi, Хk) + d(Хk, Хj), unde Хj; Xi și Xk sunt oricare trei vectori din Ep.
Valoarea d(Хi, Хj) pentru Хi și Хj se numește distanța dintre Хi și Хj și este echivalentă cu distanța dintre Gi și Gj în funcție de caracteristicile selectate (F1, F2, F3, ..., Fр).
Cele mai frecvent utilizate funcții de distanță sunt:
1. Distanța euclidiană
2. l1 - normă
4. Supremum este norma
dҐ (Хi , Хj) = sup
k = 1, 2, ..., p
5. lp - normă
dр(Хi, Хj) =
Metrica euclidiană este cea mai populară. Valoarea l1 este cea mai ușor de calculat. Norma supremă este ușor de calculat și include o procedură de comandă, iar norma lp acoperă funcțiile de distanță 1, 2, 3,.
Fie reprezentate n dimensiuni X1, X2,..., Xn ca o matrice de date de dimensiunea pґn:
Atunci distanța dintre perechile de vectori d(Хi, Хj) poate fi reprezentată ca o matrice simetrică a distanțelor:
Conceptul opus distanței este conceptul de similitudine între obiectele Gi. iar Gj. O funcție reală nenegativă S(Хi ; Хj) = Sij se numește măsură de similitudine dacă:
1) 0Ј S(Хi, Хj)<1 для Хi № Хj
2) S(Хi, Хi) = 1
3) S(Хi, Хj) = S(Хj, Хi)
Perechile de valori de măsurare a similitudinii pot fi combinate într-o matrice de similaritate:
Valoarea Sij se numește coeficient de similitudine.
2. Metode de analiză a clusterelor
Metodele de analiză a clusterelor pot fi împărțite în două grupe:
* ierarhic;
* neierarhic.
Fiecare grup include multe abordări și algoritmi.
Folosind diferite tehnici de analiză de cluster, un analist poate obține soluții diferite pentru aceleași date. Acest lucru este considerat normal. Să luăm în considerare metodele ierarhice și non-ierarhice în detaliu.
Esența grupării ierarhice este de a combina secvențial grupuri mai mici în altele mai mari sau de a împărți grupuri mari în altele mai mici.
Metode aglomerative ierarhice (Agglomerative Nesting, AGNES) Acest grup de metode se caracterizează prin combinarea secvenţială a elementelor iniţiale şi o reducere corespunzătoare a numărului de clustere.
La începutul algoritmului, toate obiectele sunt grupuri separate. În primul pas, cele mai asemănătoare obiecte sunt combinate într-un grup. În pașii următori, fuziunea continuă până când toate obiectele formează un grup. Metode ierarhice divizibile (divizibile) (ANALIZA DIVISIVE, DIANA) Aceste metode sunt opusul logic al metodelor aglomerative. La începutul algoritmului, toate obiectele aparțin unui grup, care în pașii următori este împărțit în grupuri mai mici, rezultând o succesiune de grupuri de împărțire.
Metodele non-ierarhice dezvăluie o stabilitate mai mare în ceea ce privește zgomotul și valorile aberante, alegerea incorectă a metricilor și includerea variabilelor nesemnificative în setul care participă la grupare. Prețul care trebuie plătit pentru aceste avantaje ale metodei este cuvântul „a priori”. Analistul trebuie să predetermina numărul de clustere, numărul de iterații sau regula de oprire și alți parametri de clustering. Acest lucru este deosebit de dificil pentru începători.
Dacă nu există ipoteze privind numărul de clustere, se recomandă utilizarea algoritmilor ierarhici. Cu toate acestea, dacă dimensiunea eșantionului nu permite acest lucru, o modalitate posibilă este de a efectua o serie de experimente cu numere diferite de clustere, de exemplu, începeți împărțirea setului de date cu două grupuri și, crescând treptat numărul acestora, comparați rezultatele. Datorită acestei „variații” a rezultatelor, se obține o flexibilitate destul de mare a grupării.
Metodele ierarhice, spre deosebire de cele non-ierarhice, refuză să determine numărul de clustere, dar construiesc un arbore complet de clustere imbricate.
Dificultăți ale metodelor de grupare ierarhică: limitarea dimensiunii setului de date; alegerea măsurii de proximitate; inflexibilitatea clasificărilor rezultate.
Avantajul acestui grup de metode în comparație cu metodele neierarhice este vizibilitatea lor și capacitatea de a obține o înțelegere detaliată a structurii datelor.
Atunci când se utilizează metode ierarhice, este posibil să se identifice destul de ușor valorile aberante într-un set de date și, ca urmare, să se îmbunătățească calitatea datelor. Această procedură stă la baza algoritmului de grupare în doi pași. Un astfel de set de date poate fi utilizat ulterior pentru a realiza clustering non-ierarhic.
Există un alt aspect care a fost deja menționat în această prelegere. Aceasta este o chestiune de grupare a întregului set de date sau a unui eșantion din acesta. Acest aspect este esențial pentru ambele grupuri de metode luate în considerare, dar este mai critic pentru metodele ierarhice. Metodele ierarhice nu pot funcționa cu seturi mari de date, iar utilizarea unor eșantionări, de ex. părți ale datelor ar putea permite aplicarea acestor metode.
Rezultatele grupării pot să nu aibă o justificare statistică suficientă. Pe de altă parte, la rezolvarea problemelor de clustering este acceptabilă o interpretare non-statistică a rezultatelor obținute, precum și o varietate destul de mare de variante ale conceptului de cluster. Această interpretare non-statistică permite analistului să obțină rezultate de grupare care îl mulțumesc, ceea ce este adesea dificil atunci când se utilizează alte metode.
1) Metoda conexiunilor complete.
Esența acestei metode este că două obiecte aparținând aceluiași grup (cluster) au un coeficient de similaritate care este mai mic decât o anumită valoare de prag S. În ceea ce privește distanța euclidiană d, aceasta înseamnă că distanța dintre două puncte (obiecte) a clusterului nu trebuie să depășească o anumită valoare prag h. Astfel, h definește diametrul maxim admisibil al subsetului care formează clusterul.
2) Metoda distanței locale maxime.
Fiecare obiect este tratat ca un singur grup de puncte. Obiectele sunt grupate după următoarea regulă: două grupuri sunt combinate dacă distanța maximă dintre punctele unui grup și punctele celuilalt este minimă. Procedura constă din n - 1 pași și rezultatul sunt partiții care coincid cu toate partițiile posibile din metoda anterioară pentru orice valoare de prag.
3) Metoda cuvântului.
În această metodă, suma intragrup a abaterilor pătrate este utilizată ca funcție obiectiv, care nu este altceva decât suma distanțelor pătrate dintre fiecare punct (obiect) și media grupului care conține acest obiect. La fiecare pas, două clustere sunt combinate care duc la o creștere minimă a funcției obiectiv, adică. suma de pătrate în cadrul grupului. Această metodă are ca scop combinarea clusterelor strâns localizate.
4) Metoda centroidă.
Distanța dintre două clustere este definită ca distanța euclidiană dintre centrele (mediile) acestor clustere:
d2 ij = (`X -`Y)Т(`X -`Y) Clustering are loc în etape: la fiecare dintre cei n-1 pași se combină două clustere G și p, având o valoare minimă d2ij Dacă n1 este mult mai mare decât n2, atunci centrele unirii celor două clustere sunt apropiate unul de celălalt, iar caracteristicile celui de-al doilea cluster sunt practic ignorate la combinarea clusterelor. Această metodă este uneori numită și metoda grupului ponderat.
3. Dendograme
Cea mai cunoscută metodă de reprezentare a unei matrice de distanță sau similaritate se bazează pe ideea unei dendograme sau diagramă arborescentă. O dendogramă poate fi definită ca o reprezentare grafică a rezultatelor unui proces de grupare secvenţială, care se realizează în termenii unei matrice de distanţe. Folosind o dendogramă, puteți reprezenta grafic sau geometric o procedură de clustering, cu condiția ca această procedură să opereze numai pe elemente ale matricei de distanță sau similaritate.
Există multe moduri de a construi dendograme. Într-o dendogramă, obiectele sunt situate vertical în stânga, rezultatele grupării sunt situate în dreapta. Valorile distanței sau similarității corespunzătoare structurii noilor clustere sunt reprezentate de-a lungul unei linii orizontale deasupra dendogramelor.
Figura 1 prezintă un exemplu de dendogramă. Figura 1 corespunde cazului a șase obiecte (n=6) și k caracteristici (trăsături). Obiectele A și C sunt cele mai apropiate și, prin urmare, sunt combinate într-un singur grup la un nivel de proximitate de 0,9. Obiectele D și E sunt combinate la nivelul 0,8. Acum avem 4 clustere:
Tipul dendogramei depinde de alegerea măsurii de similitudine sau de distanța dintre un obiect și un cluster și de metoda de grupare. Cel mai important punct este alegerea măsurii de similitudine sau a distanței dintre obiect și cluster.
Numărul de algoritmi de analiză a clusterelor este prea mare. Toate pot fi împărțite în ierarhice și neierarhice.
Algoritmii ierarhici sunt asociați cu construcția dendogramelor și sunt împărțiți în:
a) aglomerativ, caracterizat prin combinarea secvențială a elementelor inițiale și o scădere corespunzătoare a numărului de clustere;
b) divizibil (divizibil), în care numărul de clustere crește, începând de la unul, rezultând formarea unei secvențe de grupuri de scindare.
Algoritmii de analiză a clusterelor au astăzi implementări software bune care permit rezolvarea problemelor de cea mai mare dimensiune.
Concluzie
Analiza cluster este un instrument foarte convenabil pentru identificarea segmentelor de piață. Mai ales în epoca noastră de înaltă tehnologie, când mașinile vin în ajutorul unei persoane, un astfel de proces care necesită forță de muncă devine literalmente o chestiune de secunde.
Formarea segmentelor depinde de datele disponibile și nu este determinată în prealabil.
Variabilele care formează baza grupării ar trebui selectate pe baza experienței studiilor anterioare, a fondului teoretic, a ipotezelor testate și la discreția cercetătorului. În plus, trebuie selectată o măsură adecvată a distanței (similarității). O caracteristică a grupării ierarhice este dezvoltarea unei structuri ierarhice sau arborescente. Metodele de grupare ierarhică pot fi aglomerative sau divizionare. Metodele aglomerative includ: metoda legăturii simple, metoda legăturii complete și metoda legăturii medii. O metodă de dispersie utilizată pe scară largă este metoda Bard. Metodele de grupare non-ierarhice sunt adesea numite metode k-means. Aceste metode includ metoda pragului secvenţial, metoda pragului paralel şi optimizarea alocării. Metodele ierarhice și non-ierarhice pot fi utilizate împreună. Alegerea metodei de grupare și alegerea măsurării distanței sunt interdependente.
Decizia asupra numărului de clustere se ia din motive teoretice și practice. În gruparea ierarhică, un criteriu important pentru a decide numărul de clustere este distanțele la care clusterele se îmbină. Dimensiunile relative ale clusterelor ar trebui să fie astfel încât să aibă sens să păstrăm un anumit cluster, mai degrabă decât să îl îmbinați cu altele. Clusterele sunt interpretate în termeni de centroizi de cluster. Clusterele sunt adesea interpretate prin profilarea lor prin variabile care nu au stat la baza grupării. Fiabilitatea și validitatea soluțiilor de clustering sunt evaluate în diferite moduri.
dendogramă aglomerativă ierarhică cluster
Referințe
1. Vasiliev V.I. și altele. Analiza statistică a obiectelor de natură arbitrară. Introducere în statistica calității - M.: ICAR, 2004.
2. Analiză economică şi statistică / Ed. Ilyenkova S.D. -M.: UNTIT, 2002.
3. Parsadanov G.A. Prognoza si planificarea sistemului socio-economic al tarii - M.: UNITI, 2001
Postat pe Allbest.ru
Programare liniară. Interpretare geometrică și metodă grafică de rezolvare a ZLP. Metoda simplex pentru rezolvarea PLP. Metoda pe bază artificială. Algoritmul metodei elementului minim. Algoritmul metodei potențiale. metoda Gomori. Algoritmul metodei Vogel.
rezumat, adăugat la 02.03.2009
Metoda grafica de rezolvare a problemei de optimizare a proceselor de productie. Aplicarea unui algoritm simplex pentru a rezolva o problemă de management al producției optimizată din punct de vedere economic. Metodă de programare dinamică pentru selectarea profilului de traseu optim.
test, adaugat 15.10.2010
Metode analitice și numerice de optimizare neconstrânsă. Metoda eliminării și metoda multiplicatorului Lagrange (LMM). Metoda lui Euler este o metodă clasică de rezolvare a problemelor de optimizare neconstrânsă. Problemă clasică de optimizare constrânsă. Despre semnificația practică a MML.
rezumat, adăugat 17.11.2010
Metode de bază pentru rezolvarea problemelor de programare liniară. Metoda grafică, metoda simplex. Problemă dublă, metodă potențială. Modelarea și caracteristicile rezolvării unei probleme de transport folosind metoda potențială folosind capabilitățile Microsoft Excel.
test, adaugat 14.03.2014
Tipuri de manifestare a relaţiilor cantitative dintre caracteristici. Definiții ale conexiunilor funcționale și corelaționale. Semnificația practică a stabilirii, direcției și tăriei corelației. Metoda pătratelor (metoda Pearson), metoda rangului (metoda Spearman).
prezentare, adaugat 19.04.2015
O metodă geometrică pentru rezolvarea problemelor standard de programare liniară cu două variabile. O metodă universală de rezolvare a problemei canonice. Ideea principală a metodei simplex, implementare folosind un exemplu. Implementarea tabelară a unei metode simplex simple.
rezumat, adăugat 15.06.2010
O soluție de suport inițială evidentă. Metoda simplex pe bază naturală. Metodă grafică pentru rezolvarea problemelor de programare liniară. Problemă dublă, soluția sa optimă. Matricea raportului costurilor. Schema completă a echilibrului inter-industrial.
test, adaugat 30.04.2009
Obiectivele segmentării pieței în activități de marketing. Esența analizei cluster, principalele etape ale implementării acesteia. Selectarea unei metode de măsurare a distanței sau a unei măsuri de similitudine. Metode de grupare ierarhică și non-ierarhică. Evaluarea fiabilității și validității.
raport, adaugat 11.02.2009
Meta analizei cluster: înțelegere, algoritm, proiectare. Principalele caracteristici ale procedurii McKean. Graficul valorilor medii pentru trei grupuri. Metoda K-metode, avantajele și dezavantajele studiului. Înțelegerea algoritmilor de grupare a rețelei (bazate pe grilă).
rezumat, adăugat 27.05.2013
Teoria matematică a deciziei optime. Metoda simplex tabelar. Formularea și rezolvarea unei probleme de programare liniară duală. Modelul matematic al problemei transportului. Analiza fezabilității producției la întreprindere.
Universitatea Tehnică de Stat Mari
Departamentul RTiMBS
Analiza clusterelor
Ghid pentru munca de laborator
Yoshkar-Ola
200 8
Introducere
Partea teoretică
Problemă de analiză a clusterelor
Metode de analiză a clusterelor
Algoritmi de grupare
Numărul de clustere
Dendograme
Partea practică
Exemplu
Exemplu de soluție în programSPSS 11.0
Exemplu de soluție în programSTATISTICA
Sarcina de laborator
Concluzie
Referințe
Aplicație
Introducere
Un grup mare de probleme de analiză a datelor bazate pe utilizarea metodelor statistice sunt așa-numitele probleme de clasificare. Există trei subdomeni ale teoriei clasificării: discriminare (analiza discriminantă), grupare (analiza cluster) și grupare.
Scopul principal al analizei cluster este de a împărți setul de obiecte și caracteristici studiate în grupuri sau clustere care sunt omogene în sensul corespunzător. Aceasta înseamnă că problema clasificării datelor și identificării structurii corespunzătoare din acestea este în curs de rezolvare. Metodele de analiză a clusterelor pot fi utilizate într-o mare varietate de cazuri, chiar și în cazurile în care vorbim de grupare simplă, în care totul se rezumă la formarea de grupuri pe baza similitudinii cantitative.
Marele avantaj al analizei cluster este că vă permite să divizați obiectele nu în funcție de un parametru, ci în funcție de un întreg set de caracteristici. În plus, analiza cluster, spre deosebire de majoritatea metodelor matematice și statistice, nu impune nicio restricție asupra tipului de obiecte luate în considerare și permite să se ia în considerare o varietate de date inițiale de natură aproape arbitrară.
Analiza cluster vă permite să luați în considerare o cantitate destul de mare de informații și să reduceți și să comprimați în mod dramatic cantități mari de informații, făcându-le compacte și vizuale.
Analiza cluster poate fi utilizată iterativ. În acest caz, cercetarea se efectuează până la obținerea rezultatelor necesare. Mai mult, fiecare ciclu de aici poate oferi informații care pot schimba foarte mult direcția și abordările pentru aplicarea ulterioară a analizei cluster. Acest proces poate fi reprezentat ca un sistem de feedback.
Diferitele aplicații ale analizei cluster pot fi reduse la patru sarcini principale:
elaborarea unei tipologii sau clasificări;
explorarea schemelor conceptuale utile pentru gruparea obiectelor;
generarea de ipoteze bazate pe cercetarea datelor;
testarea ipotezelor sau cercetarea pentru a determina dacă tipurile (grupurile) identificate într-un fel sau altul sunt de fapt prezente în datele disponibile.
Tehnicile de grupare sunt utilizate într-o mare varietate de domenii. Hartigan (1975) a oferit o revizuire excelentă a multor studii publicate care conţin rezultate obţinute prin metodele de analiză a grupurilor. De exemplu, în domeniul medicinei, gruparea bolilor, tratamentele pentru boli sau simptomele bolilor duce la taxonomii utilizate pe scară largă. În domeniul psihiatriei, diagnosticarea corectă a grupurilor de simptome precum paranoia, schizofrenia etc. este crucială pentru succesul terapiei.
Dezavantajele analizei cluster:
Multe metode de analiză a clusterelor sunt proceduri destul de simple care, de regulă, nu au o justificare statistică suficientă
Metodele de analiză în clustere au fost dezvoltate pentru multe discipline științifice și, prin urmare, poartă amprenta specificului acestor discipline.
Metode de cluster diferite pot genera și generează soluții diferite pentru aceleași date.
Scopul analizei cluster este de a găsi structuri existente. În același timp, efectul său este de a introduce structura în datele analizate, adică metodele de grupare sunt necesare pentru a detecta structura în date care nu este ușor de găsit prin inspecție vizuală sau cu ajutorul experților.
Universitatea: VZFEI
Anul și orașul: Moscova 2008
1. Introducere. Conceptul de metoda analizei cluster.
2. Descrierea metodologiei de utilizare a analizei cluster. Exemplu de testare de rezolvare a problemelor.
4. Lista referințelor utilizate
Analiza cluster este un set de metode care fac posibilă clasificarea observațiilor multidimensionale, fiecare dintre acestea fiind descrisă de un set de caracteristici (parametri) X1, X2,…, Xk.
Scopul analizei cluster este formarea de grupuri de obiecte similare, care sunt de obicei numite clustere (clasă, taxon, condensare).
Analiza clusterelor este unul dintre domeniile cercetării statistice. Ocupă un loc deosebit de important în acele ramuri ale științei care sunt asociate cu studiul fenomenelor și proceselor de masă. Necesitatea de a dezvolta metode de analiză a clusterelor și utilizarea lor este dictată de faptul că acestea ajută la construirea clasificărilor bazate științific și la identificarea conexiunilor interne între unitățile populației observate. În plus, metodele de analiză a clusterelor pot fi utilizate pentru comprimarea informațiilor, care este un factor important în contextul creșterii constante și complexității fluxurilor de date statistice.
Metodele de analiză a clusterelor vă permit să rezolvați următoarele probleme:
Efectuarea clasificării obiectelor luând în considerare caracteristicile care reflectă esența și natura obiectelor. Rezolvarea unei astfel de probleme, de regulă, duce la aprofundarea cunoștințelor despre totalitatea obiectelor clasificate;
Verificarea ipotezelor făcute cu privire la prezența unei structuri în setul de obiecte studiat, i.e. căutarea unei structuri existente;
Construirea de noi clasificări pentru fenomene slab studiate, atunci când este necesar să se stabilească prezența legăturilor în cadrul unei populații și să se încerce introducerea structurii în ea (1, pp. 85-86).
2. Descrierea metodologiei de utilizare a analizei cluster. Exemplu de testare de rezolvare a problemelor.
Analiza cluster permite ca n obiecte caracterizate prin k caracteristici să fie împărțite în grupuri omogene (clustere). Omogenitatea obiectelor este determinată de distanța p(xi xj), unde xi = (xi1, …., xik) și xj= (xj1,…, xjk) sunt vectori formați din valorile k caracteristici ale i -lea și respectiv j-lea obiecte.
Pentru obiectele caracterizate prin caracteristici numerice, distanța este determinată de următoarea formulă:
p(xi , xj) = √ ∑(x1m-xjm) 2 (1)*
Obiectele sunt considerate omogene dacă p(xi xj)< p предельного.
O reprezentare grafică a uniunii poate fi obținută folosind un arbore de unire cluster - o dendrogramă. (2. Capitolul 39).
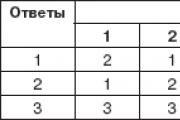
Caz de testare (exemplul 92).
|
Volumul vânzărilor |
|||||
Să clasificăm aceste obiecte folosind principiul „cel mai apropiat vecin”. Să găsim distanțele dintre obiecte folosind formula (1)*. Să completăm tabelul.
Să explicăm cum este completat tabelul.
La intersecția rândului i și coloanei j, este indicată distanța p(xi xj) (rezultatul este rotunjit la două zecimale).
De exemplu, la intersecția rândului 1 și coloanei 3 este indicată distanța p(x1, x3) = √(1-6) 2 +(9-8) 2 ≈ 5,10, iar la intersecția rândului 3 și coloanei 5 distanța p(x3 , x5) = √ (6-12) 2 + (8-7) 2 ≈ 6,08. Deoarece p(xi, xj) = p(xj,xi), partea inferioară a tabelului nu trebuie completată.
Să aplicăm principiul „cel mai apropiat vecin”. Găsim în tabel cea mai mică dintre distanțe (dacă sunt mai multe, atunci alegeți oricare dintre ele). Acesta este p 1,2 ≈ p 4,5 = 2,24. Fie p min = p 4,5 = 2,24. Apoi putem combina obiectele 4 și 5 într-un singur grup, adică coloana combinată 4 și 5 va avea cel mai mic dintre numerele corespunzătoare din coloanele 4 și 5 din tabelul de distanțe inițial. Facem același lucru cu rândurile 4 și 5. Obținem un tabel nou.
Găsim în tabelul rezultat cea mai mică dintre distanțe (dacă sunt mai multe, atunci alegeți oricare dintre ele): p min = p 1,2 = 2,24. Apoi putem combina obiectele 1,2,3 într-un singur grup, adică coloana combinată 1,2,3 va conține cel mai mic dintre numărul corespunzător de coloane 1 și 2 și 3 din tabelul de distanțe anterior. Facem același lucru cu rândurile 1, 2 și 3. Obținem un nou tabel.
Avem două grupuri: (1,2,3) și (4,5).
3. Rezolvarea problemelor pentru test.
Problema 85.
Conditii: Cinci unități de producție se caracterizează prin două caracteristici: volumul vânzărilor și costul mediu anual al activelor fixe de producție.
|
Volumul vânzărilor |
|||||
|
Costul mediu anual al mijloacelor fixe |
Soluţie: Să găsim distanțele dintre obiecte folosind formula (1)* (rotunjind la două zecimale):
р 1,1 = √ (2-2) 2 + (2-2) 2 = 0
р 1,2 = √ (2-5) 2 + (7-9) 2 ≈ 3,61
р 1,3 = √ (2-7) 2 + (7-10) 2 ≈ 5,83
p 2.2 = √ (5-5) 2 + (9-9) 2 =0
р 2,3 = √ (5-7) 2 + (9-10) 2 ≈ 2,24
p 3,4 = √ (7-12) 2 + (10-8) 2 ≈5,39
p 3,5 = √ (7-13) 2 + (10-5) 2 ≈ 7,81
p 4,5 = √ (12-13) 2 + (8-5) 2 ≈ 3,16
Pe baza rezultatelor calculului, completați tabelul:
Să aplicăm principiul „cel mai apropiat vecin”. Pentru a face acest lucru, găsim cea mai mică dintre distanțe din tabel (dacă există mai multe astfel de distanțe, atunci selectați oricare dintre ele). Acesta este p 2,3=2,24. Fie p min = p 2,3 = 2,24, apoi putem îmbina obiectele coloanelor „2” și „3”, precum și șirurile de obiecte „2” și „3”. În noul tabel, introducem cele mai mici valori din tabelul original în grupurile combinate.
În noul tabel găsim cea mai mică dintre distanțe (dacă sunt mai multe, atunci selectați oricare dintre ele). Acesta este p 4,5 = 3,16. Fie p min = p 4,5 = 3,16, apoi putem îmbina obiectele coloanelor „4” și „5”, precum și șirurile de obiecte „4” și „5”. În noul tabel, introducem cele mai mici valori din tabelul original în grupurile combinate.
În noul tabel găsim cea mai mică dintre distanțe (dacă sunt mai multe, atunci selectați oricare dintre ele). Acesta este p 1, 2 și 3 = 3,61. Fie p min = p 1, 2 și 3 = 3,61, apoi putem îmbina obiectele coloană „1” și „2 și 3” și, de asemenea, putem îmbina rândurile. În noul tabel, introducem cele mai mici valori din tabelul original în grupurile combinate.
Obținem două grupuri: (1,2,3) și (4,5).
Dendrograma arată ordinea de selecție a elementelor și distanțele minime corespunzătoare p min.
Răspuns: Ca rezultat al analizei cluster folosind principiul „cel mai apropiat vecin”, s-au format 2 clustere de obiecte similare: (1,2,3) și (4,5).
Problema 211.
Conditii: Cinci unități de producție se caracterizează prin două caracteristici: volumul vânzărilor și costul mediu anual al mijloacelor fixe.
|
Volumul vânzărilor |
|||||
|
Costul mediu anual al mijloacelor fixe |
Clasificați aceste obiecte folosind principiul „cel mai apropiat vecin”.
Soluţie: Pentru a rezolva problema, prezentăm datele în tabelul original. Să determinăm distanțele dintre obiecte. Să clasificăm obiectele după principiul „cel mai apropiat vecin”. Prezentăm rezultatele sub forma unei dendrograme.
|
Volumul vânzărilor |
|||||
|
Costul mediu anual al mijloacelor fixe |
Folosind formula (1)* găsim distanțele dintre obiecte:
p 1,1 =0, p 1,2 =6, p 1,3 =8,60, p 1,4 =6,32, p 1,5 =6,71, p 2,2 =0, p 2 .3 =7,07, p 2,4 =2, p 2,5 =3,32, p 3,3 = 0, p 3,4 =5,10, p 3,5 =4,12, p 4,4 =0, p 4,5 =1, p 5,5 =0.
Prezentăm rezultatele în tabel:
Cea mai mică valoare a distanțelor din tabel este p 4,5=1. Fie p min = p 4,5 = 1, apoi putem îmbina obiectele coloanelor „4” și „5”, precum și șirurile de obiecte „4” și „5”. În noul tabel, introducem cele mai mici valori din tabelul original în grupurile combinate.
Cea mai mică valoare a distanțelor din noul tabel este p 2, 4 și 5=2. Fie p min = p 2, 4 și 5=2, apoi putem îmbina obiectele coloanelor „4 și 5” și „3”, precum și rândurile obiectelor „4 și 5” și „3”. În noul tabel, introducem cele mai mici valori din tabel în grupurile combinate.
Cea mai mică valoare a distanțelor din noul tabel este p 3,4,5=2. Fie p min = p 3,4,5=2, apoi putem îmbina obiectele coloanelor „3,4,5” și „2” și, de asemenea, unim rândurile obiectelor „3,4,5” și „2”. În noul tabel, introducem cele mai mici valori din tabel în grupurile combinate.
| sau conectați-vă la site. |
1 . Adrianov A.Yu., Linzen L., Clusterele ca instrument pentru dezvoltarea organizațiilor non-profit // www.dis.ru.
2. Alimbaev A.A., Pritvorova T.P., Taubaev A.A. Formarea și dezvoltarea clusterelor în condițiile dezvoltării industriale și inovatoare a Republicii Kazahstan // www.liter.kz
3. Notă analitică pentru iulie-august 2006 a organului teritorial al Serviciului Federal de Stat de Statistică pentru regiunea Astrakhan
4. Bludova S.N. Clusterele regionale ca modalitate de gestionare a complexului economic extern al regiunii // www.ncstu.ru
5. Borodatov A.V., Kozhevnikova V.D. Inițiativa de creare a unui cluster turistic și de agrement Sevastopol // Partener de afaceri. - 2004. - Nr. 10. - Cu. 33-37.
6. Buryak A.P., Voropov A.G. Analiza clusterelor - baza managementului competitivitatii la nivel macro // Marketing. - 2003. - Nr. 1. - Cu. 34-40.
7. Davydov A.R., Lyalkina G.B. Noi forme de organizare a procesului de inovare. Experiență internațională // www.dis.ru
8. Dranev Y.N. Abordarea cluster a dezvoltării economice a teritoriilor. - M.: Editura „Scanrus”, 2003. - 195 p.
9. Zasimova L.S. Ratele de creștere a producției din industria alimentară în regiunea Astrakhan // www.volgainform.ru
10. Kapustin A.N. Investiții în turism: calitate versus cantitate // www. astrakhan.net
11. Kutin V.M. Agruparea economică teritorială (clasificarea) regiunilor rusești: aspect socio-geografic // Securitatea Eurasiei. - 2003. - Nr. 1. - Cu. 21-28.
12. Lee S. Clusters - noi forme de organizare a procesului de inovare // www.naukakaz.kz.
13. Lozinsky S., Prazdnichnykh A. Competitivitate și clustere industriale: o nouă agendă pentru afacerile și guvernul rusesc // World of Construction Industry. - 2003. - Nr. 2. - Cu. 32-41.
14. Martynov L.M. Ratele de creștere a producției din industria alimentară în regiunea Astrakhan // www.caspy.net
15. Melnikova S.V. Baza pentru prosperitatea turismului din Astrahan este o politică specială de mediu // Turismul în Rusia. - 2006. - Nr. 8. - Cu. 31-35.
16. Migranian A.A. Aspecte teoretice ale formării clusterelor competitive // www.dis.ru.
17. Mikheev Yu.V., Khasaev G.R. Clustere prin parteneriat spre viitor // www.ptpu.ru.
18. Nikolaev M.V. Concentrarea clusterului de integrare eficientă a regiunilor în economia globală // www.subcontract.ru
19. Perkina M.V. Afacerea hotelieră ia stele din cer // Astrakhanskie Vedomosti. - 2006. - Nr. 19. - Cu. 3.
20. Porter M.E. Concurenta: Per. din engleză: Uch. sat - M.: Editura Williams, 2000. - 495 p.
21. Porter M. Concurs internaţional. - M.: Internațional. relaţii, 1993.- 869 p.
22. Decretul Guvernului Regiunii Astrakhan nr. 368-P din 2510.2006 privind programul țintă sectorial „Dezvoltarea turismului în Regiunea Astrakhan pentru anul 2007”.
23. Program de dezvoltare socio-economică a regiunii Astrakhan, luând în considerare dublarea produsului regional brut pentru 2005-2007.
24. Sviridov A.P. Eco-turismul poate salva regiunea Astrakhan // www.volga-astrakhan.ru
25. Simachev Yu.V. Clustering ca modalitate de a asigura competitivitatea regiunii // www.clusters-net.ru
26. Sokolenko S.I. De la cercetarea clusterelor la dezvoltarea structurilor comerciale și de producție în rețea // Russian Economic Journal. - 2004. - Nr. 6. - Cu. 10-15.
27. Sokolenko S.I. Dezvoltarea clusterelor turistice și recreative: inițiativa regională a Ucrainei // Regiunea. - 2004. - Nr. 2. - Cu. 19-22.
28. Spankulova L.S. Probleme de dezvoltare a economiei clusterelor a industriei la nivel regional // AlPari. - 2004. - Nr. 2. - Cu. 16-
29. Anuarul statistic al dezvoltării socio-economice a regiunii Astrakhan 2004, 2005 / Organul teritorial al Serviciului Federal de Stat de Statistică pentru regiunea Astrakhan
30. Steblyakova L.P. Probleme de creare și dezvoltare a clusterelor economice: experiența țărilor străine // Proceedings of the Karaganda University of Business, Management and Law. - 2005. - Nr. 2. - Cu. 22-29.
31. Steblyakova L.P., Vechkinzova E.A. Formarea clusterelor de competitivitate în Kazahstanul central // www.liter.kz
32. Plan strategic de dezvoltare a formațiunii municipale „Orașul Astrakhan” pentru 2005 - 2010.
33. Strategia de dezvoltare a turismului în regiunea Astrakhan pe termen mediu și lung, 2005.
34. Filippov P. Clustere de competitivitate // Expert. - 2003.- Nr. 43. - Cu. 10-15.
35. Tsikhan T.V. Teoria clusterelor a dezvoltării economice // Teoria și practica managementului. - 2003. - Nr. 5. - Cu. 22-25.
36 . Ciorapi A.A. Mecanisme de creștere a competitivității economiilor regionale // www.subcontract.ru
37. Shehovtsova L.S. Clusterul ca instrument modern pentru creșterea competitivității în regiune // www.clusters-net.ru
38. www.astrahanpages.com
39. www.astrasocial.ru
40. www. astrgorod.ru
41. www. astrobl.ru
42. www. asttour.ru
43. www.economy.astrobl.ru

Elena Shishkina Prezentare „Ziua Pământului” Prezentare „Ziua Pământului”. Scop: să formeze idei că planeta...

Sunteți interesat de un post vacant postat pe un site de angajare. Ce să faci mai departe? Specialisti in cautarea de locuri de munca...

Abilitățile profesionale și calitățile personale sunt un punct obligatoriu la completarea unei cereri sau pentru orice post vacant. ÎN...

Un test poate răspunde la o întrebare complexă - cine am fost într-o viață trecută, ce am făcut și ce fel de viață am dus. Mai jos sunt...
Scale: stiluri de luare a deciziilor de management: laissez-faire, marginal, implementator, autoritar,...
La dezvoltarea unei afaceri, este foarte dificil să evitați o creștere necorespunzătoare a personalului. Cu cât întreprinderea este mai mare, cu atât mai mult...

Anii de naștere: 1927, 1959, 1991, 2023, 2055 Culoare: Albastru-verde Simbolismul semnului: Nemurire, longevitate,...
Pentru a introduce cu succes documentul de concediere, vom verifica setările programului 1C 8.3 pentru a evita erorile în...

Kaizen (改善 kaizen) este o filozofie sau practică japoneză care se concentrează pe continuu...

Slide 2 OBIECTIVUL LECȚIEI Educațional: Să-i învețe pe elevi să în mod independent (folosind instrucțiunile și tehnologia...

A fost odată un preot cu o frunte groasă. Preotul s-a dus la bazar să se uite la niște mărfuri. Balda vine spre el, nu spre el...

În octombrie 2008, după premiera în rețea a sequel-ului filmului de conspirație al lui Peter Joseph Zeitgeist...

Toată lumea știe că fără experiență de muncă este imposibil să găsești un post bun vacant. Daca nu il ai, nu-l omite...

Principala modalitate de automatizare a proceselor de prelucrare mecanică a pieselor pentru producția la scară mică și individuală...

Sunteți interesat de un post vacant postat pe un site de angajare. Ce să faci mai departe? Cauta specialisti...

Abilitățile profesionale și calitățile personale sunt un punct obligatoriu la completarea unui formular de cerere sau pentru orice...