Communicative universal learning activities
1 of 34 Presentation - Formation of communicative learning activities through the technology of educational cooperation The text of this...
The term “cluster analysis” was first used by the American psychologist Robert Tryon in his work of the same name back in 1930. Despite this, the terms “cluster” and “cluster analysis” are perceived by native speakers as new, as noted by Alexander Khrolenko, who conducted a corpus analysis of the use of the lexeme “cluster”: “most authors using this term pay attention to its novelty” (Khrolenko , 2016, p. 106)
Cluster analysis includes many different classification algorithms, the purpose of which is to organize information into clusters. It is important to remember that cluster analysis is not a specific algorithm in itself, but a problem that needs to be solved. In his work “The Scarcity of Linear Hierarchy,” Mark Ereshefsky notes that cluster analysis is one of three types of classification of objects in the surrounding world, along with essentialism and historical classification.
In linguistics, the cluster principle of description implies, in addition to the analysis of the units included in this cluster, also the analysis of the relationships within them. These can be connections at different levels: from logical (paradigmatic and syntagmatic, for example) to word-formation and phonetic connections.
F. Brown outlines the following steps cluster analysis(Brown):
It should be noted that the third point raises questions, since the distinctive feature of clustering as a classification method is the absence of specified classes. Document clustering is an information retrieval task. Unlike text categorization, it does not involve predefined categories or a training set. Clusters and the relationships between them are “automatically extracted from documents, and documents are sequentially assigned to these clusters” (Golub, pp. 52-53) Mark Ereshefsky introduces cluster analysis as a classification method. He believes that "all forms of cluster analysis are based on two assumptions: members of a taxonomic group must have a cluster of traits in common, and those traits cannot appear in all or just one member of that group." (Ereshefsky, p. 15)
In his work “Cluster approach in linguistic analysis” (Nurgalieva, 2013) N.Kh. Nurgalieva identifies four main tasks of cluster analysis:
All methods of cluster analysis can be divided into “hard”, clear cluster analysis, when each object either belongs to a cluster or not, and into “soft”, fuzzy cluster analysis, when each object belongs to some group with a certain degree of probability.
Cluster analysis methods are also divided into hierarchical and non-hierarchical. Hierarchical methods imply the presence of nested groups, unlike non-hierarchical methods. Nurgalieva notes that the hierarchical method “seems to be the most suitable for solving linguistic problems” (Nurgalieva, p. 1), since it allows you to see and analyze the structure of the phenomenon being studied.
Students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
Posted on http://www.allbest.ru/
Introduction
1. Definition and tasks of cluster analysis
2. Cluster analysis methods
3. Dendograms
Conclusion
References
Introduction
Cluster analysis is a set of methods that allow you to classify multidimensional observations. The term cluster analysis, first introduced by Tryon in 1939, includes more than 100 different algorithms.
Unlike classification problems, cluster analysis does not require a priori assumptions about the data set, does not impose restrictions on the representation of the objects under study, and allows you to analyze indicators various types data (interval data, frequencies, binary data). It must be remembered that the variables must be measured on comparable scales.
Cluster analysis allows you to reduce the dimension of data and make it clearer.
Cluster analysis is used to identify groups of points in data that are clearly different from each other. The importance of solving this problem is due to the fact that the use of standard data analysis tools (including standard econometric procedures) in the presence of clusters in the data will lead to a shift in both point estimates (regression coefficients) and standard errors, and therefore to incorrect statistical conclusions. In addition, the structure of the data and the similarity of observations may be of independent interest.
Cluster analysis is designed to divide a set of objects into homogeneous groups (clusters or classes). In essence, this is a problem of multidimensional data classification.
1. Definition and tasks of cluster analysis
When analyzing and forecasting socio-economic phenomena, the researcher quite often encounters the multidimensionality of their description. This occurs when solving the problem of market segmentation, constructing a typology of countries based on a sufficiently large number of indicators, and forecasting market conditions individual goods, studying and forecasting economic depression and many other problems.
Multivariate analysis methods are the most effective quantitative tool for studying socio-economic processes described by a large number of characteristics. These include cluster analysis, taxonomy, pattern recognition, factor analysis.
Cluster analysis most clearly reflects the features of multidimensional analysis in classification, factor analysis - in the study of communication.
Sometimes the cluster analysis approach is called in the literature numerical taxonomy, numerical classification, self-learning recognition, etc.
Cluster analysis found its first application in sociology. The name cluster analysis comes from English word cluster - bunch, accumulation. For the first time in 1939, the subject of cluster analysis was defined and described by researcher Trion. The main purpose of cluster analysis is to divide the set of objects and characteristics under study into groups or clusters that are homogeneous in the appropriate sense. This means that the problem of classifying data and identifying the corresponding structure in it is being solved. Cluster analysis methods can be used in a wide variety of cases, even in cases where we are talking about simple grouping, in which everything comes down to the formation of groups based on quantitative similarity.
The great advantage of cluster analysis is that it allows you to split objects not according to one parameter, but according to a whole set of characteristics. In addition, cluster analysis, unlike most mathematical and statistical methods, does not impose any restrictions on the type of objects under consideration, and allows one to consider a variety of initial data of an almost arbitrary nature. It has great value, for example, for forecasting the market situation, when the indicators have a diverse form, making it difficult to use traditional econometric approaches.
Cluster analysis allows you to consider a fairly large amount of information and dramatically reduce and compress large amounts of socio-economic information, making them compact and visual.
Cluster analysis is important in relation to sets of time series characterizing economic development(for example, general economic and commodity conditions). Here you can highlight periods when the values of the corresponding indicators were quite close, and also determine groups of time series whose dynamics are most similar.
Cluster analysis can be used iteratively. In this case, the research is carried out until the necessary results are achieved. Moreover, each cycle here can provide information that can greatly change the direction and approaches to the further application of cluster analysis. This process can be represented as a feedback system.
In tasks of socio-economic forecasting, the combination of cluster analysis with other quantitative methods (for example, regression analysis) is very promising.
Like any other method, cluster analysis has certain disadvantages and limitations: In particular, the composition and number of clusters depends on the selected partition criteria. When reducing the original data array to a more compact form, certain distortions may occur, and the individual features of individual objects may be lost due to their replacement with the characteristics of generalized values of the cluster parameters. When classifying objects, the possibility of the absence of any cluster values in the set under consideration is very often ignored.
In cluster analysis it is considered that:
a) the selected characteristics allow, in principle, the desired division into clusters;
b) the units of measurement (scale) are chosen correctly.
The choice of scale plays a big role. Typically, data is normalized by subtracting the mean and dividing by the standard deviation so that the variance is equal to one.
The task of cluster analysis is to, based on the data contained in the set X, divide the set of objects G into m (m is an integer) clusters (subsets) Q1, Q2, ..., Qm, so that each object Gj belongs to one and only one subset of the partition and so that objects belonging to the same cluster are similar, while objects belonging to different clusters are heterogeneous.
For example, let G include n countries, any of which is characterized by GNP per capita (F1), the number M of cars per 1 thousand people (F2), per capita electricity consumption (F3), per capita steel consumption (F4), etc. Then X1 (measurement vector) is a set of specified characteristics for the first country, X2 for the second, X3 for the third, etc. The goal is to categorize countries by level of development.
The solution to the cluster analysis problem is partitions that satisfy some optimality criterion. This criterion can be some kind of functional expressing the levels of desirability of various partitions and groupings, which is called the objective function. For example, the within-group sum of squared deviations can be taken as the objective function:
where xj represents the measurements of the j-th object.
To solve the problem of cluster analysis, it is necessary to define the concept of similarity and heterogeneity.
It is clear that objects i-th and j-th would fall into one cluster when the distance (remoteness) between points Xi and Xj would be small enough and would fall into different clusters when this distance would be large enough. Thus, falling into one or different clusters of objects is determined by the concept of the distance between Xi and Xj from Ep, where Ep is a p-dimensional Euclidean space. A non-negative function d(Xi, Xj) is called a distance function (metric) if:
a) d(Хi, Хj) і 0, for all Хi and Хj from Ep
b) d(Хi, Хj) = 0, if and only if Хi = Хj
c) d(Хi, Хj) = d(Хj, Хi)
d) d(Хi, Хj) Ј d(Хi, Хk) + d(Хk, Хj), where Хj; Xi and Xk are any three vectors from Ep.
The value d(Хi, Хj) for Хi and Хj is called the distance between Хi and Хj and is equivalent to the distance between Gi and Gj according to the selected characteristics (F1, F2, F3, ..., Fр).
The most commonly used distance functions are:
1. Euclidean distance
2. l1 - norm
4. Supremum is the norm
dҐ (Хi , Хj) = sup
k = 1, 2, ..., p
5. lp - norm
dр(Хi, Хj) =
The Euclidean metric is the most popular. The l1 metric is the easiest to calculate. The supremum norm is easy to calculate and includes an ordering procedure, and the lp norm covers the distance functions 1, 2, 3,.
Let n dimensions X1, X2,..., Xn be represented as a data matrix of size pґ n:
Then the distance between pairs of vectors d(Хi, Хj) can be represented as a symmetric matrix of distances:
The opposite concept to distance is the concept of similarity between objects Gi. and Gj. A non-negative real function S(Хi ; Хj) = Sij is called a similarity measure if:
1) 0Ј S(Хi, Хj)<1 для Хi № Хj
2) S(Хi, Хi) = 1
3) S(Хi, Хj) = S(Хj, Хi)
Pairs of similarity measure values can be combined into a similarity matrix:
The value Sij is called the similarity coefficient.
2. Cluster analysis methods
Cluster analysis methods can be divided into two groups:
* hierarchical;
* non-hierarchical.
Each group includes many approaches and algorithms.
Using different cluster analysis techniques, an analyst can obtain different solutions for the same data. This is considered normal. Let us consider hierarchical and non-hierarchical methods in detail.
The essence of hierarchical clustering is to sequentially combine smaller clusters into larger ones or divide large clusters into smaller ones.
Hierarchical agglomerative methods (Agglomerative Nesting, AGNES) This group of methods is characterized by the sequential combination of initial elements and a corresponding reduction in the number of clusters.
At the beginning of the algorithm, all objects are separate clusters. In the first step, the most similar objects are combined into a cluster. In subsequent steps, the merging continues until all objects form one cluster. Hierarchical divisible (divisible) methods (DIvisive ANAlysis, DIANA) These methods are the logical opposite of agglomerative methods. At the beginning of the algorithm, all objects belong to one cluster, which in subsequent steps is divided into smaller clusters, resulting in a sequence of splitting groups.
Non-hierarchical methods reveal higher stability with respect to noise and outliers, incorrect choice of metrics, and inclusion of insignificant variables in the set participating in clustering. The price that has to be paid for these advantages of the method is the word “a priori”. The analyst must determine in advance the number of clusters, the number of iterations or stopping rule, and some other clustering parameters. This is especially difficult for beginners.
If there are no assumptions regarding the number of clusters, it is recommended to use hierarchical algorithms. However, if the sample size does not allow this, a possible way is to conduct a series of experiments with different numbers of clusters, for example, start splitting the data set with two groups and, gradually increasing their number, compare the results. Due to this “variation” of results, a fairly large flexibility of clustering is achieved.
Hierarchical methods, unlike non-hierarchical ones, refuse to determine the number of clusters, but build a complete tree of nested clusters.
Difficulties of hierarchical clustering methods: limitation of data set size; choice of proximity measure; inflexibility of the resulting classifications.
The advantage of this group of methods in comparison with non-hierarchical methods is their visibility and the ability to obtain a detailed understanding of the data structure.
When using hierarchical methods, it is possible to quite easily identify outliers in a data set and, as a result, improve the quality of the data. This procedure underlies the two-step clustering algorithm. Such a data set can later be used to carry out non-hierarchical clustering.
There is another aspect that has already been mentioned in this lecture. This is a matter of clustering the entire data set or a sample of it. This aspect is essential for both groups of methods under consideration, but it is more critical for hierarchical methods. Hierarchical methods cannot work with large data sets, and the use of some sampling, e.g. parts of the data could allow these methods to be applied.
Clustering results may not have sufficient statistical justification. On the other hand, when solving clustering problems, a non-statistical interpretation of the results obtained is acceptable, as well as a fairly large variety of variants of the concept of a cluster. This non-statistical interpretation allows the analyst to obtain clustering results that satisfy him, which is often difficult when using other methods.
1) Method of complete connections.
The essence of this method is that two objects belonging to the same group (cluster) have a similarity coefficient that is less than a certain threshold value S. In terms of the Euclidean distance d, this means that the distance between two points (objects) of the cluster should not exceed a certain threshold value h. Thus, h defines the maximum allowable diameter of the subset that forms the cluster.
2) Maximum local distance method.
Each object is treated as a single point cluster. Objects are grouped according to the following rule: two clusters are combined if the maximum distance between the points of one cluster and the points of the other is minimal. The procedure consists of n - 1 steps and the result is partitions that coincide with all possible partitions in the previous method for any threshold values.
3) Word's method.
In this method, the intragroup sum of squared deviations is used as the objective function, which is nothing more than the sum of squared distances between each point (object) and the average of the cluster containing this object. At each step, two clusters are combined that lead to a minimal increase in the objective function, i.e. within-group sum of squares. This method aims to combine closely located clusters.
4) Centroid method.
The distance between two clusters is defined as the Euclidean distance between the centers (averages) of these clusters:
d2 ij = (`X -`Y)Т(`X -`Y) Clustering occurs step by step at each of the n-1 steps, two clusters G and p are combined, having a minimum value d2ij If n1 is much greater than n2, then the centers of the union of the two clusters are close to each other and the characteristics of the second cluster are practically ignored when combining clusters. This method is sometimes also called the weighted group method.
3. Dendograms
The most well-known method for representing a distance or similarity matrix is based on the idea of a dendogram or tree diagram. A dendogram can be defined as a graphical representation of the results of a sequential clustering process, which is carried out in terms of a distance matrix. Using a dendogram, you can graphically or geometrically represent a clustering procedure, provided that this procedure operates only on elements of the distance or similarity matrix.
There are many ways to construct dendograms. In a dendogram, objects are located vertically on the left, clustering results are located on the right. Distance or similarity values corresponding to the structure of new clusters are depicted along a horizontal line on top of the dendograms.
Figure 1 shows one example of a dendogram. Figure 1 corresponds to the case of six objects (n=6) and k characteristics (features). Objects A and C are the closest and therefore are combined into one cluster at a proximity level of 0.9. Objects D and E are combined at level 0.8. Now we have 4 clusters:
The type of dendogram depends on the choice of similarity measure or distance between an object and a cluster and the clustering method. The most important point is the choice of similarity measure or distance measure between the object and the cluster.
The number of cluster analysis algorithms is too large. All of them can be divided into hierarchical and non-hierarchical.
Hierarchical algorithms are associated with the construction of dendograms and are divided into:
a) agglomerative, characterized by the sequential combination of initial elements and a corresponding decrease in the number of clusters;
b) divisible (divisible), in which the number of clusters increases, starting from one, resulting in the formation of a sequence of splitting groups.
Cluster analysis algorithms today have good software implementation, which allows solving problems of the largest dimension.
Conclusion
Cluster analysis is a very convenient tool for identifying market segments. Especially in our age of high technology, when machines come to the aid of a person, such a labor-intensive process becomes literally a matter of seconds.
The formation of segments depends on the available data and is not determined in advance.
Variables that form the basis for clustering should be selected based on the experience of previous studies, theoretical background, hypotheses being tested, and at the discretion of the researcher. In addition, an appropriate measure of distance (similarity) should be selected. A feature of hierarchical clustering is the development of a hierarchical or tree structure. Hierarchical clustering methods can be agglomerative or divisional. Agglomerative methods include: single bond method, complete bond method and medium bond method. A widely used dispersion method is the Bard method. Non-hierarchical clustering methods are often called k-means methods. These methods include sequential threshold method, parallel threshold method, and optimizing allocation. Hierarchical and non-hierarchical methods can be used together. The choice of clustering method and the choice of distance measure are interrelated.
The decision on the number of clusters is made for theoretical and practical reasons. In hierarchical clustering, an important criterion for deciding on the number of clusters is the distances at which clusters merge. The relative sizes of clusters should be such that it makes sense to preserve a given cluster rather than merge it with others. Clusters are interpreted in terms of cluster centroids. Clusters are often interpreted by profiling them through variables that were not the basis for clustering. The reliability and validity of clustering solutions are assessed in different ways.
cluster hierarchical agglomerative dendogram
References
1. Vasiliev V.I. and others. Statistical analysis of objects of arbitrary nature. Introduction to quality statistics. - M.: ICAR, 2004.
2. Economic and statistical analysis / Ed. Ilyenkova S.D. -M.: UNTIT, 2002.
3. Parsadanov G.A. Forecasting and planning of the country's socio-economic system. - M.: UNITI, 2001
Posted on Allbest.ru
Linear programming. Geometric interpretation and graphical method for solving ZLP. Simplex method for solving LLP. Artificial basis method. Algorithm of the minimum element method. Algorithm of the potential method. Gomori method. Algorithm of the Vogel method.
abstract, added 02/03/2009
Graphical method for solving the problem of optimization of production processes. Application of a simplex algorithm to solve an economically optimized production management problem. Dynamic programming method for selecting the optimal path profile.
test, added 10/15/2010
Analytical and numerical methods of unconstrained optimization. Elimination method and Lagrange multiplier method (LMM). Euler's method is a classic method for solving unconstrained optimization problems. Classical constrained optimization problem. About the practical meaning of MML.
abstract, added 11/17/2010
Basic methods for solving linear programming problems. Graphic method, simplex method. Dual problem, potential method. Modeling and features of solving a transport problem using the potential method using the capabilities of Microsoft Excel.
test, added 03/14/2014
Types of manifestation of quantitative relationships between characteristics. Definitions of functional and correlational connections. The practical significance of establishing, direction and strength of correlation. Method of squares (Pearson method), rank method (Spearman method).
presentation, added 04/19/2015
A geometric method for solving standard linear programming problems with two variables. A universal method for solving the canonical problem. The main idea of the simplex method, implementation using an example. Tabular implementation of a simple simplex method.
abstract, added 06/15/2010
An obvious initial support solution. Simplex method with natural basis. Graphical method for solving linear programming problems. Dual problem, its optimal solution. Cost ratio matrix. Complete scheme of inter-industry balance.
test, added 04/30/2009
Goals of market segmentation in marketing activities. The essence of cluster analysis, the main stages of its implementation. Selecting a distance measurement method or a similarity measure. Hierarchical, non-hierarchical clustering methods. Assessing reliability and validity.
report, added 11/02/2009
Meta of cluster analysis: understanding, algorithm, design. Main features of the McKean procedure. Graph of average values for three clusters. Method of K-methods, advantages and shortcomings of the study. Understanding about grid clustering algorithms (grid-based).
abstract, added 05/27/2013
Mathematical theory of optimal decision making. Tabular simplex method. Formulation and solution of a dual linear programming problem. Mathematical model of the transport problem. Analysis of the feasibility of production at the enterprise.
Mari State Technical University
Department of RTiMBS
Cluster analysis
Guidelines for laboratory work
Yoshkar-Ola
200 8
Introduction
Theoretical part
Cluster Analysis Problem
Cluster analysis methods
Clustering algorithms
Number of clusters
Dendograms
Practical part
Example
Example solution in the programSPSS 11.0
Example solution in the programSTATISTICA
Laboratory assignment
Conclusion
References
Application
Introduction
A large group of data analysis problems based on the use of statistical methods are the so-called classification problems. There are three subfields of classification theory: discrimination (discriminant analysis), clustering (cluster analysis) and grouping.
The main purpose of cluster analysis is to divide the set of objects and characteristics under study into groups or clusters that are homogeneous in the appropriate sense. This means that the problem of classifying data and identifying the corresponding structure in it is being solved. Cluster analysis methods can be used in a wide variety of cases, even in cases where we are talking about simple grouping, in which everything comes down to the formation of groups based on quantitative similarity.
The great advantage of cluster analysis is that it allows you to split objects not according to one parameter, but according to a whole set of characteristics. In addition, cluster analysis, unlike most mathematical and statistical methods, does not impose any restrictions on the type of objects under consideration, and allows one to consider a variety of initial data of an almost arbitrary nature.
Cluster analysis allows you to consider a fairly large amount of information and dramatically reduce and compress large amounts of information, making them compact and visual.
Cluster analysis can be used iteratively. In this case, the research is carried out until the necessary results are achieved. Moreover, each cycle here can provide information that can greatly change the direction and approaches to the further application of cluster analysis. This process can be represented as a feedback system.
The various applications of cluster analysis can be reduced to four main tasks:
development of a typology or classification;
exploration of useful conceptual schemes for grouping objects;
generating hypotheses based on data research;
hypothesis testing or research to determine whether the types (groups) identified in one way or another are actually present in the available data.
Clustering techniques are used in a wide variety of fields. Hartigan (1975) gave an excellent review of many published studies containing results obtained by cluster analysis methods. For example, in the field of medicine, clustering of diseases, treatments for diseases, or symptoms of diseases leads to widely used taxonomies. In the field of psychiatry, correct diagnosis of symptom clusters such as paranoia, schizophrenia, etc. is crucial for successful therapy.
Disadvantages of cluster analysis:
Many cluster analysis methods are quite simple procedures that, as a rule, do not have sufficient statistical justification
Cluster analysis methods have been developed for many scientific disciplines, and therefore bear the imprints of the specifics of these disciplines.
Different cluster methods can and do generate different solutions for the same data.
The purpose of cluster analysis is to find existing structures. At the same time, its effect is to introduce structure into the analyzed data, i.e., clustering methods are necessary to detect structure in data that is not easy to find by visual inspection or with the help of experts.
University: VZFEI
Year and city: Moscow 2008
1. Introduction. The concept of cluster analysis method.
2. Description of the methodology for using cluster analysis. Test example of problem solving.
4. List of references used
Cluster analysis is a set of methods that make it possible to classify multidimensional observations, each of which is described by a set of characteristics (parameters) X1, X2,…, Xk.
The goal of cluster analysis is the formation of groups of similar objects, which are usually called clusters (class, taxon, condensation).
Cluster analysis is one of the areas of statistical research. It occupies a particularly important place in those branches of science that are associated with the study of mass phenomena and processes. The need to develop methods of cluster analysis and their use is dictated by the fact that they help build scientifically based classifications and identify internal connections between units of the observed population. In addition, cluster analysis methods can be used to compress information, which is an important factor in the context of the constant increase and complexity of statistical data flows.
Cluster analysis methods allow you to solve the following problems:
Carrying out classification of objects taking into account features that reflect the essence and nature of objects. Solving such a problem, as a rule, leads to deepening knowledge about the totality of classified objects;
Checking the assumptions made about the presence of some structure in the studied set of objects, i.e. search for an existing structure;
Construction of new classifications for poorly studied phenomena, when it is necessary to establish the presence of connections within a population and try to introduce structure into it (1, pp. 85-86).
2. Description of the methodology for applying cluster analysis. Test example of problem solving.
Cluster analysis allows n objects characterized by k features to be divided into homogeneous groups (clusters). The homogeneity of objects is determined by the distance p(xi xj), where xi = (xi1, …., xik) and xj= (xj1,…, xjk) are vectors composed of the values of k features of the i-th and j-th objects, respectively.
For objects characterized by numerical characteristics, the distance is determined by the following formula:
p(xi , xj) = √ ∑(x1m-xjm) 2 (1)*
Objects are considered homogeneous if p(xi xj)< p предельного.
A graphical representation of the union can be obtained using a cluster union tree - a dendrogram. (2. Chapter 39).
Test case (example 92).
|
Sales volume |
|||||
Let us classify these objects using the “nearest neighbor” principle. Let's find the distances between objects using formula (1)*. Let's fill out the table.
Let us explain how the table is filled out.
At the intersection of row i and column j, the distance p(xi xj) is indicated (the result is rounded to two decimal places).
For example, at the intersection of row 1 and column 3 the distance p(x1, x3) = √(1-6) 2 +(9-8) 2 ≈ 5.10 is indicated, and at the intersection of row 3 and column 5 the distance p(x3 , x5) = √ (6-12) 2 + (8-7) 2 ≈ 6.08. Since p(xi, xj) = p(xj,xi), the lower part of the table need not be filled out.
Let us apply the “nearest neighbor” principle. We find in the table the smallest of the distances (if there are several of them, then choose any of them). This is p 1.2 ≈ p 4.5 = 2.24. Let p min = p 4.5 = 2.24. Then we can combine objects 4 and 5 into one group, that is, the combined column 4 and 5 will have the smallest of the corresponding numbers in columns 4 and 5 of the original distance table. We do the same with lines 4 and 5. We get a new table.
We find in the resulting table the smallest of the distances (if there are several of them, then choose any of them): p min = p 1.2 = 2.24. Then we can combine objects 1,2,3 into one group, that is, the combined column 1,2,3 will contain the smallest of the corresponding numbers of columns 1 and 2 and 3 of the previous distance table. We do the same with rows 1, 2 and 3. We get a new table.
We got two clusters: (1,2,3) and (4,5).
3. Solving problems for the test.
Problem 85.
Conditions: Five production facilities are characterized by two characteristics: sales volume and the average annual cost of fixed assets.
|
Sales volume |
|||||
|
Average annual cost of fixed assets |
Solution: Let's find the distances between objects using formula (1)* (rounding to two decimal places):
р 1,1 = √ (2-2) 2 + (2-2) 2 = 0
р 1.2 = √ (2-5) 2 + (7-9) 2 ≈ 3.61
р 1.3 = √ (2-7) 2 + (7-10) 2 ≈ 5.83
p 2.2 = √ (5-5) 2 + (9-9) 2 =0
р 2.3 = √ (5-7) 2 + (9-10) 2 ≈ 2.24
p 3.4 = √ (7-12) 2 + (10-8) 2 ≈5.39
p 3.5 = √ (7-13) 2 + (10-5) 2 ≈ 7.81
p 4.5 = √ (12-13) 2 + (8-5) 2 ≈ 3.16
Based on the calculation results, fill out the table:
Let us apply the “nearest neighbor” principle. To do this, we find the smallest of the distances in the table (if there are several such distances, then select any of them). This is p 2.3=2.24. Let p min = p 2.3 = 2.24, then we can merge the objects of columns “2” and “3”, and also merge the rows of objects “2” and “3”. In the new table, we enter the smallest values from the original table into the combined groups.
In the new table we find the smallest of the distances (if there are several of them, then select any of them). This is p 4.5 = 3.16. Let p min = p 4.5 = 3.16, then we can merge the objects of columns “4” and “5”, and also merge the rows of objects “4” and “5”. In the new table, we enter the smallest values from the original table into the combined groups.
In the new table we find the smallest of the distances (if there are several of them, then select any of them). This is p 1, 2 and 3 = 3.61. Let p min = p 1, 2 and 3 = 3.61, then we can merge column objects "1" and "2 and 3" and also merge rows. In the new table, we enter the smallest values from the original table into the combined groups.
We get two clusters: (1,2,3) and (4,5).
The dendrogram shows the order of selection of elements and the corresponding minimum distances p min.
Answer: As a result of cluster analysis using the “nearest neighbor” principle, 2 clusters of similar objects were formed: (1,2,3) and (4,5).
Problem 211.
Conditions: Five production facilities are characterized by two characteristics: sales volume and the average annual cost of fixed assets.
|
Sales volume |
|||||
|
Average annual cost of fixed assets |
Classify these objects using the “nearest neighbor” principle.
Solution: To solve the problem, we present the data in the original table. Let's determine the distances between objects. Let us classify objects according to the “nearest neighbor” principle. We present the results in the form of a dendrogram.
|
Sales volume |
|||||
|
Average annual cost of fixed assets |
Using formula (1)* we find the distances between objects:
p 1.1 =0, p 1.2 =6, p 1.3 =8.60, p 1.4 =6.32, p 1.5 =6.71, p 2.2 =0, p 2 .3 =7.07, p 2.4 =2, p 2.5 =3.32, p 3.3 =0, p 3.4 =5.10, p 3.5 =4.12, p 4 .4 =0, p 4.5 =1, p 5.5 =0.
We present the results in the table:
The smallest value of the distances in the table is p 4.5=1. Let p min = p 4.5 = 1, then we can merge the objects of columns “4” and “5”, and also merge the rows of objects “4” and “5”. In the new table, we enter the smallest values from the original table into the combined groups.
The smallest value of the distances in the new table is p 2, 4 and 5=2. Let p min = p 2, 4 and 5=2, then we can merge the objects of the columns "4 and 5" and "3", and also merge the rows of the objects "4 and 5" and "3". In the new table, we enter the smallest values from the table into the combined groups.
The smallest value of the distances in the new table is p 3,4,5=2. Let p min = p 3,4,5=2, then we can merge the objects of the columns “3,4,5” and “2”, and also merge the rows of the objects “3,4,5” and “2”. In the new table, we enter the smallest values from the table into the combined groups.
| or log in to the site. |
1 . Adrianov A.Yu., Linzen L., Clusters as a tool for the development of non-profit organizations // www.dis.ru.
2. Alimbaev A.A., Pritvorova T.P., Taubaev A.A. Formation and development of clusters in the conditions of industrial and innovative development of the Republic of Kazakhstan // www.liter.kz
3. Analytical note for July-August 2006 of the Territorial body of the Federal State Statistics Service for the Astrakhan region
4. Bludova S.N. Regional clusters as a way to manage the foreign economic complex of the region // www.ncstu.ru
5. Borodatov A.V., Kozhevnikova V.D. Initiative to create a Sevastopol tourist and recreational cluster // Business partner. - 2004. - No. 10. - With. 33-37.
6. Buryak A.P., Voropov A.G. Cluster analysis - the basis for managing competitiveness at the macro level // Marketing. - 2003. - No. 1. - With. 34-40.
7. Davydov A.R., Lyalkina G.B. New forms of organizing the innovation process. International experience // www.dis.ru
8. Dranev Y.N. Cluster approach to economic development of territories. - M.: Publishing house "Scanrus", 2003. - 195 p.
9. Zasimova L.S. Growth rates of food industry production in the Astrakhan region // www.volgainform.ru
10. Kapustin A.N. Tourism investments: quality versus quantity // www. astrakhan.net
11. Kutin V.M. Territorial economic clustering (classification) of Russian regions: socio-geographical aspect // Security of Eurasia. - 2003. - No. 1. - With. 21-28.
12. Lee S. Clusters - new forms of organizing the innovation process // www.naukakaz.kz.
13. Lozinsky S., Prazdnichnykh A. Competitiveness and industry clusters: a new agenda for Russian business and government // World of Construction Industry. - 2003. - No. 2. - With. 32-41.
14. Martynov L.M. Growth rates of food industry production in the Astrakhan region // www.caspy.net
15. Melnikova S.V. The basis for the prosperity of Astrakhan tourism is a special environmental policy // Tourism in Russia. - 2006. - No. 8. - With. 31-35.
16. Migranyan A.A. Theoretical aspects of the formation of competitive clusters // www.dis.ru.
17. Mikheev Yu.V., Khasaev G.R. Clusters through partnership towards the future // www.ptpu.ru.
18. Nikolaev M.V. Cluster concentration of effective integration of regions into the global economy // www.subcontract.ru
19. Perkina M.V. The hotel business takes stars from the sky // Astrakhanskie Vedomosti. - 2006. - No. 19. - With. 3.
20. Porter M.E. Competition: Per. from English: Uch. village - M.: Williams Publishing House, 2000. - 495 p.
21. Porter M. International competition. - M.: International. relations, 1993.- 869 p.
22. Decree of the Government of the Astrakhan Region No. 368-P dated 2510.2006 on the sectoral target program “Development of tourism in the Astrakhan Region for 2007”.
23. Program for the socio-economic development of the Astrakhan region, taking into account doubling the gross regional product for 2005-2007.
24. Sviridov A.P. Eco-tourism can save the Astrakhan region // www.volga-astrakhan.ru
25. Simachev Yu.V. Clustering as a way to ensure the competitiveness of the region // www.clusters-net.ru
26. Sokolenko S.I. From cluster research to the development of network commercial and production structures // Russian Economic Journal. - 2004. - No. 6. - With. 10-15.
27. Sokolenko S.I. Development of tourist and recreational clusters: regional initiative of Ukraine // Region. - 2004. - No. 2. - With. 19-22.
28. Spankulova L.S. Problems of development of cluster economics of industry at the regional level // AlPari. - 2004. - No. 2. - With. 16-
29. Statistical yearbook of socio-economic development of the Astrakhan region 2004, 2005 / Territorial body of the Federal State Statistics Service for the Astrakhan region
30. Steblyakova L.P. Problems of creation and development of economic clusters: experience of foreign countries // Proceedings of the Karaganda University of Business, Management and Law. - 2005. - No. 2. - With. 22-29.
31. Steblyakova L.P., Vechkinzova E.A. Formation of competitiveness clusters in central Kazakhstan // www.liter.kz
32. Strategic plan for the development of the municipal formation "City of Astrakhan" for 2005 - 2010.
33. Strategy for the development of tourism in the Astrakhan region for the medium and long term, 2005.
34. Filippov P. Competitiveness clusters // Expert. - 2003.- No. 43. - With. 10-15.
35. Tsihan T.V. Cluster theory of economic development // Theory and practice of management. - 2003. - No. 5. - With. 22-25.
36 . Stocking A.A. Mechanisms for increasing the competitiveness of regional economies // www.subcontract.ru
37. Shekhovtsova L.S. Cluster as a modern tool for increasing competitiveness in the region // www.clusters-net.ru
38. www.astrahanpages.com
39. www.astrasocial.ru
40. www. astrgorod.ru
41. www. astrobl.ru
42. www. asttour.ru
43. www.economy.astrobl.ru

1 of 34 Presentation - Formation of communicative learning activities through the technology of educational cooperation The text of this...

Presentation "Migratory Birds" for preschool children and primary school students. Migratory birds gather in...

Slide presentation Slide text: Pneumonia Slide text: Pneumonia is an acute infectious disease...

The term "forecast" means foresight, prediction. Forecasting is the process of making a forecast of the development of certain...

Slide 1-2 Learning motivation is a process that initiates, directs and supports efforts aimed at...

Existing remuneration systems in modern enterprises are very diverse and sometimes differ significantly....
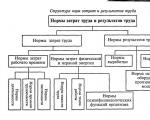
Labor standards determine the measure of remuneration for work. With a time-based wage system, the amount of wages...

Abstract: 86 pp., 3 figures, 15 tables, 40 sources, 7 appendices. MARKETING, MARKETING MANAGEMENT, ENTERPRISE,...

Agreement for the use of site materials Please use the works published on the site...

Slide 1 We are veterinarians! Presentation on the topic: “My future profession” was prepared by students of group 2 Vet “B”...

Fried meat will always taste better than boiled or steamed meat. Of course, what is it worth...

Presentation for OPK lesson No. 2 (grade 4) “Religion is an integral part of culture and people’s lives” based on the textbook by A.V....

summary of presentations Theory of evolution Slides: 35 Words: 3086 Sounds: 0 Effects: 0 Neo-Darwinism and...

Today, many people are thinking about becoming a hairdresser. After all, experts in cutting, styling and coloring...

Presentation "Migratory Birds" for preschool children and primary school students. Migratory birds...

Slide presentation Slide text: Pneumonia Slide text: Pneumonia is an acute infectious disease...