Презентация на тема "Денят на Земята"
Елена Шишкина Презентация „Денят на Земята“ Презентация „Денят на Земята“. Цел: формиране на идеи, че планетата...
Терминът „клъстерен анализ“ е използван за първи път от американския психолог Робърт Трайън в едноименната му работа през 1930 г. Въпреки това термините „клъстер“ и „клъстерен анализ“ се възприемат от носителите на езика като нови, както отбелязва Александър Хроленко, който извърши анализ на корпуса на употребата на лексемата „клъстер“: „повечето автори, използващи този термин, обръщат внимание към неговата новост” (Хроленко, 2016, стр. 106)
Клъстерният анализ включва много различни алгоритми за класификация, чиято цел е да организира информацията в клъстери. Важно е да запомните, че клъстерният анализ не е специфичен алгоритъм сам по себе си, а проблем, който трябва да бъде разрешен. В своята работа „Недостигът на линейна йерархия“ Марк Ерешевски отбелязва, че клъстерният анализ е един от трите вида класификация на обекти в околния свят, заедно с есенциализма и историческата класификация.
В лингвистиката клъстерният принцип на описание предполага, в допълнение към анализа на единиците, включени в този клъстер, и анализ на връзките в тях. Това могат да бъдат връзки на различни нива: от логически (парадигматични и синтагматични, например) до словообразувателни и фонетични връзки.
Ф. Браун очертава следните стъпки клъстерен анализ(кафяв):
Трябва да се отбележи, че третата точка повдига въпроси, тъй като отличителната черта на групирането като класификационен метод е липсата на определени класове. Групирането на документи е задача за извличане на информация. За разлика от категоризацията на текст, тя не включва предварително дефинирани категории или набор за обучение. Клъстерите и връзките между тях се „извличат автоматично от документи и документите се присвояват последователно на тези клъстери“ (Голуб, стр. 52-53). Марк Ерешевски въвежда клъстерния анализ като класификационен метод. Той вярва, че "всички форми на клъстерен анализ се основават на две предположения: членовете на една таксономична група трябва да имат група от общи черти и тези черти не могат да се появят във всички или само в един член на тази група." (Ерешевски, стр. 15)
В работата си „Клъстерен подход в лингвистичния анализ” (Нургалиева, 2013) Н.Х. Нургалиева идентифицира четири основни задачи на клъстерния анализ:
Всички методи за клъстерен анализ могат да бъдат разделени на „твърд“, ясен клъстерен анализ, когато всеки обект или принадлежи към клъстер или не, и на „мек“, размит клъстерен анализ, когато всеки обект принадлежи към някаква група с определена степен на вероятност.
Методите за клъстерен анализ също се разделят на йерархични и нейерархични. Йерархичните методи предполагат наличието на вложени групи, за разлика от нейерархичните методи. Нургалиева отбелязва, че йерархичният метод „изглежда най-подходящ за решаване на лингвистични проблеми“ (Нургалиева, стр. 1), тъй като ви позволява да видите и анализирате структурата на изучаваното явление.
Студенти, докторанти, млади учени, които използват базата от знания в обучението и работата си, ще ви бъдат много благодарни.
Публикувано на http://www.allbest.ru/
Въведение
1. Определение и задачи на клъстерния анализ
2. Методи за клъстерен анализ
3. Дендограми
Заключение
Референции
Въведение
Клъстерен анализе набор от методи, които ви позволяват да класифицирате многоизмерни наблюдения. Терминът клъстерен анализ, въведен за първи път от Tryon през 1939 г., включва повече от 100 различни алгоритми.
За разлика от проблемите с класификацията, клъстерният анализ не изисква априорни предположения за набора от данни, не налага ограничения върху представянето на изследваните обекти и ви позволява да анализирате индикатори различни видоведанни (интервални данни, честоти, двоични данни). Трябва да се помни, че променливите трябва да се измерват в сравними скали.
Клъстерният анализ ви позволява да намалите размерността на данните и да ги направите по-ясни.
Клъстерният анализ се използва за идентифициране на групи от точки в данните, които са ясно различни една от друга. Важността на решаването на този проблем се дължи на факта, че използването на стандартни инструменти за анализ на данни (включително стандартни иконометрични процедури) при наличие на клъстери в данните ще доведе до промяна както в точковите оценки (регресионни коефициенти), така и в стандартните грешки, и следователно до неверни статистически заключения. В допълнение, структурата на данните и сходството на наблюденията могат да бъдат от независим интерес.
Клъстерният анализ е предназначен да раздели набор от обекти на хомогенни групи (клъстери или класове). По същество това е многоизмерен проблем за класификация на данни.
1. Дефиниция и задачи на клъстерния анализ
При анализа и прогнозирането на социално-икономическите явления изследователят често се сблъсква с многоизмерността на тяхното описание. Това се случва при решаване на проблема със сегментирането на пазара, изграждане на типология на страните въз основа на достатъчно голям брой показатели и прогнозиране на пазарните условия отделни стоки, изучаване и прогнозиране на икономическа депресия и много други проблеми.
Методите за многомерен анализ са най-ефективният количествен инструмент за изследване на социално-икономическите процеси, описвани с голям брой характеристики. Те включват клъстерен анализ, таксономия, разпознаване на модели, факторен анализ.
Клъстерният анализ най-ясно отразява характеристиките на многомерния анализ в класификацията, факторния анализ - в изследването на комуникацията.
Понякога подходът на клъстерния анализ се нарича в литературата числова таксономия, числена класификация, самообучаващо се разпознаване и др.
Клъстерният анализ намери своето първо приложение в социологията. Името клъстерен анализ идва от английска думаклъстер - грозд, натрупване. За първи път през 1939 г. предметът на клъстерния анализ е дефиниран и описан от изследователя Трион. Основната цел на клъстерния анализ е да раздели набора от изследвани обекти и характеристики на групи или клъстери, които са хомогенни в подходящия смисъл. Това означава, че проблемът с класифицирането на данните и идентифицирането на съответната структура в тях се решава. Методите за клъстерен анализ могат да се използват в най-различни случаи, дори в случаите, когато говорим за просто групиране, при което всичко се свежда до формирането на групи на базата на количествено сходство.
Голямото предимство на клъстерния анализ е, че ви позволява да разделяте обекти не според един параметър, а според цял набор от характеристики. В допълнение, клъстерният анализ, за разлика от повечето математически и статистически методи, не налага никакви ограничения върху типа на разглежданите обекти и позволява да се разглеждат различни първоначални данни от почти произволен характер. Има голяма стойност, например за прогнозиране на пазарната ситуация, когато индикаторите имат разнообразна форма, което затруднява използването на традиционни иконометрични подходи.
Клъстерният анализ ви позволява да разгледате доста голямо количество информация и драматично да намалите и компресирате големи количества социално-икономическа информация, което ги прави компактни и визуални.
Клъстерният анализ е важен във връзка с характеризирането на набори от времеви редове икономическо развитие(например общи икономически и стокови условия). Тук можете да маркирате периоди, когато стойностите на съответните индикатори са били доста близки, както и да определите групи от времеви редове, чиято динамика е най-сходна.
Клъстерният анализ може да се използва итеративно. В този случай изследването се провежда до постигане на необходимите резултати. Освен това всеки цикъл тук може да предостави информация, която може значително да промени посоката и подходите към по-нататъшното приложение на клъстерния анализ. Този процес може да бъде представен като система за обратна връзка.
В задачите на социално-икономическото прогнозиране комбинацията от клъстерен анализ с други количествени методи (например регресионен анализ) е много обещаваща.
Както всеки друг метод, клъстерният анализ има определени недостатъци и ограничения: По-специално, съставът и броят на клъстерите зависи от избраните критерии за разделяне. При намаляване на оригиналния масив от данни до по-компактна форма могат да възникнат определени изкривявания и индивидуалните характеристики на отделните обекти могат да бъдат загубени поради замяната им с характеристиките на обобщени стойности на параметрите на клъстера. Когато се класифицират обекти, много често се пренебрегва възможността за липса на каквито и да е клъстерни стойности в разглежданата популация.
При клъстерния анализ се счита, че:
а) избраните характеристики позволяват по принцип желаното разделяне на клъстери;
б) мерните единици (скала) са избрани правилно.
Изборът на мащаб играе голяма роля. Обикновено данните се нормализират чрез изваждане на средната стойност и разделяне на стандартното отклонение, така че дисперсията да е равна на единица.
Задачата на клъстерния анализ е въз основа на данните, съдържащи се в множеството X, да раздели множеството от обекти G на m (m е цяло число) клъстери (подмножества) Q1, Q2, ..., Qm, така че всеки обект Gj принадлежи към едно и само едно подмножество на дяла и така, че обектите, принадлежащи към един и същи клъстер, са подобни, докато обектите, принадлежащи към различни клъстери, са хетерогенни.
Например, нека G включва n страни, всяка от които се характеризира с БНП на глава от населението (F1), броя M автомобили на 1 000 души (F2), потребление на електроенергия на глава от населението (F3), потребление на стомана на глава от населението (F4) и т.н. Тогава X1 (вектор на измерване) е набор от определени характеристики за първата страна, X2 за втората, X3 за третата и т.н. Целта е да се категоризират държавите по ниво на развитие.
Решението на проблема с клъстерния анализ са дялове, които отговарят на някакъв критерий за оптималност. Този критерий може да бъде някакъв вид функционал, изразяващ нивата на желателност на различни дялове и групи, който се нарича целева функция. Например вътрешногруповата сума на квадратните отклонения може да се приеме като целева функция:
където xj представлява измерванията на j-тия обект.
За да се реши проблемът с клъстерния анализ, е необходимо да се дефинират концепциите за сходство и хетерогенност.
Ясно е, че обектите i-ти и j-ти биха попаднали в един клъстер, когато разстоянието (отдалечеността) между точките Xi и Xj би било достатъчно малко и биха попаднали в различни клъстери, когато това разстояние би било достатъчно голямо. По този начин попадането в един или различни клъстери от обекти се определя от концепцията за разстоянието между Xi и Xj от Ep, където Ep е p-измерно евклидово пространство. Неотрицателна функция d(Xi, Xj) се нарича функция на разстоянието (метрика), ако:
а) d(Хi, Хj) і 0, за всички Хi и Хj от еп
б) d(Хi, Хj) = 0, тогава и само ако Хi = Хj
в) d(Хi, Хj) = d(Хj, Хi)
г) d(Хi, Хj) Ј d(Хi, Хk) + d(Хk, Хj), където Хj; Xi и Xk са произволни три вектора от Ep.
Стойността d(Хi, Хj) за Хi и Хj се нарича разстояние между Хi и Хj и е еквивалентно на разстоянието между Gi и Gj според избраните характеристики (F1, F2, F3, ..., Fр).
Най-често използваните функции за разстояние са:
1. Евклидово разстояние
2. l1 - норма
4. Супремумът е норма
dҐ (Хi , Хj) = суп
k = 1, 2, ..., p
5. lp - норма
dр(Хi, Хj) =
Евклидовата метрика е най-популярната. Метриката l1 е най-лесната за изчисляване. Супремалната норма е лесна за изчисляване и включва процедура за подреждане, а нормата lp обхваща функциите на разстояние 1, 2, 3,.
Нека n измерения X1, X2,..., Xn са представени като матрица от данни с размер pґ n:
Тогава разстоянието между двойки вектори d(Хi, Хj) може да се представи като симетрична матрица на разстоянията:
Концепцията, противоположна на разстоянието, е концепцията за сходство между обекти Gi. и Gj. Неотрицателна реална функция S(Хi ; Хj) = Sij се нарича мярка за подобие, ако:
1) 0Ј S(Хi, Хj)<1 для Хi № Хj
2) S(Хi, Хi) = 1
3) S(Хi, Хj) = S(Хj, Хi)
Двойките от стойности на мярка за сходство могат да бъдат комбинирани в матрица за сходство:
Стойността Sij се нарича коефициент на подобие.
2. Методи за клъстерен анализ
Методите за клъстерен анализ могат да бъдат разделени на две групи:
* йерархичен;
* нейерархичен.
Всяка група включва много подходи и алгоритми.
Използвайки различни техники за клъстерен анализ, анализаторът може да получи различни решения за едни и същи данни. Това се счита за нормално. Нека разгледаме подробно йерархичните и нейерархичните методи.
Същността на йерархичното клъстериране е последователното комбиниране на по-малки клъстери в по-големи или разделяне на големи клъстери на по-малки.
Йерархични агломеративни методи (Agglomerative Nesting, AGNES) Тази група методи се характеризира с последователно комбиниране на началните елементи и съответно намаляване на броя на клъстерите.
В началото на алгоритъма всички обекти са отделни клъстери. В първата стъпка най-сходните обекти се комбинират в клъстер. В следващите стъпки сливането продължава, докато всички обекти образуват един клъстер. Йерархични делими (делими) методи (DIvisive ANAlysis, DIANA) Тези методи са логическа противоположност на агломеративните методи. В началото на алгоритъма всички обекти принадлежат към един клъстер, който в следващите стъпки се разделя на по-малки клъстери, което води до последователност от групи за разделяне.
Нейерархичните методи разкриват по-висока стабилност по отношение на шум и извънредни стойности, неправилен избор на метрики и включване на незначителни променливи в набора, участващ в клъстерирането. Цената, която трябва да се плати за тези предимства на метода, е думата „априори“. Анализаторът трябва предварително да определи броя на клъстерите, броя на итерациите или правилото за спиране и някои други параметри на клъстерите. Това е особено трудно за начинаещи.
Ако няма предположения относно броя на клъстерите, се препоръчва използването на йерархични алгоритми. Въпреки това, ако размерът на извадката не позволява това, възможен начин е да се проведат серия от експерименти с различен брой клъстери, например да започнете да разделяте набора от данни на две групи и като постепенно увеличавате техния брой, сравнете резултатите. Благодарение на тази „вариация“ на резултатите се постига доста голяма гъвкавост на клъстерирането.
Йерархичните методи, за разлика от нейерархичните, отказват да определят броя на клъстерите, а изграждат пълно дърво от вложени клъстери.
Трудности на методите за йерархично клъстериране: ограничение на размера на набора от данни; избор на мярка за близост; негъвкавост на получените класификации.
Предимството на тази група методи в сравнение с нейерархичните методи е тяхната видимост и възможността за получаване на подробно разбиране на структурата на данните.
Когато се използват йерархични методи, е възможно доста лесно да се идентифицират отклоненията в набор от данни и в резултат на това да се подобри качеството на данните. Тази процедура е в основата на алгоритъма за клъстериране в две стъпки. Такъв набор от данни може по-късно да се използва за извършване на нейерархично групиране.
Има още един аспект, който вече беше споменат в тази лекция. Това е въпрос на клъстериране на целия набор от данни или извадка от него. Този аспект е от съществено значение и за двете разглеждани групи методи, но е по-критичен за йерархичните методи. Йерархичните методи не могат да работят с големи набори от данни, а използването на някаква извадка, т.е. части от данните могат да позволят прилагането на тези методи.
Резултатите от групирането може да нямат достатъчна статистическа обосновка. От друга страна, при решаването на проблемите на клъстерирането е приемлива нестатистическа интерпретация на получените резултати, както и доста голямо разнообразие от варианти на концепцията за клъстер. Тази нестатистическа интерпретация позволява на анализатора да получи резултати от групиране, които го удовлетворяват, което често е трудно при използване на други методи.
1) Метод на пълните връзки.
Същността на този метод е, че два обекта, принадлежащи към една и съща група (клъстер), имат коефициент на сходство, който е по-малък от определена прагова стойност S. По отношение на евклидовото разстояние d това означава, че разстоянието между две точки (обекти) на клъстера не трябва да надвишава определена прагова стойност h. По този начин h определя максимално допустимия диаметър на подмножеството, което образува клъстера.
2) Метод на максимално локално разстояние.
Всеки обект се третира като клъстер от една точка. Обектите се групират по следното правило: два клъстера се комбинират, ако максималното разстояние между точките на единия клъстер и точките на другия е минимално. Процедурата се състои от n - 1 стъпки и резултатът е дялове, които съвпадат с всички възможни дялове в предишния метод за всякакви прагови стойности.
3) Методът на Word.
При този метод вътрешногруповата сума на квадратите на отклоненията се използва като целева функция, която не е нищо повече от сумата на квадратите на разстоянията между всяка точка (обект) и средната стойност на клъстера, съдържащ този обект. На всяка стъпка се комбинират два клъстера, които водят до минимално увеличение на целевата функция, т.е. сума от квадрати в рамките на групата. Този метод има за цел да комбинира близко разположени клъстери.
4) Метод на центроида.
Разстоянието между два клъстера се определя като евклидовото разстояние между центровете (средните стойности) на тези клъстери:
d2 ij = (`X -`Y)Т(`X -`Y) Клъстерирането става стъпка по стъпка на всяка от n-1 стъпки, два клъстера G и p се комбинират, имайки минимална стойност d2ij Ако n1 е много по-голямо отколкото n2, тогава центровете на обединението на двата клъстера са близо един до друг и характеристиките на втория клъстер практически се игнорират при комбиниране на клъстери. Този метод понякога се нарича още метод на претеглена група.
3. Дендограми
Най-известният метод за представяне на матрица за разстояние или подобие се основава на идеята за дендограма или дървовидна диаграма. Дендограмата може да се дефинира като графично представяне на резултатите от последователен процес на клъстериране, който се извършва по отношение на матрица на разстоянието. С помощта на дендограма можете да представите графично или геометрично процедура за групиране, при условие че тази процедура работи само върху елементи от матрицата на разстоянието или подобието.
Има много начини за конструиране на дендограми. В дендограмата обектите са разположени вертикално отляво, резултатите от групирането са разположени отдясно. Стойностите на разстоянието или сходството, съответстващи на структурата на нови клъстери, са изобразени по хоризонтална линия в горната част на дендограмите.
Фигура 1 показва един пример за дендограма. Фигура 1 съответства на случай на шест обекта (n=6) и k характеристики (характеристики). Обектите A и C са най-близките и следователно са комбинирани в един клъстер на ниво на близост от 0,9. Обекти D и E са комбинирани на ниво 0.8. Сега имаме 4 клъстера:
Типът дендограма зависи от избора на мярка за сходство или разстояние между обект и клъстер и метода на клъстериране. Най-важният момент е изборът на мярка за сходство или мярка за разстояние между обекта и клъстера.
Броят на алгоритмите за клъстерен анализ е твърде голям. Всички те могат да бъдат разделени на йерархични и нейерархични.
Йерархичните алгоритми са свързани с изграждането на дендограми и се разделят на:
а) агломеративен, характеризиращ се с последователна комбинация от първоначални елементи и съответно намаляване на броя на клъстерите;
б) делими (делими), при които броят на клъстерите се увеличава, започвайки от един, което води до образуването на последователност от разделящи се групи.
Алгоритмите за клъстерен анализ днес имат добри софтуерни реализации, които позволяват решаването на проблеми от най-голямо измерение.
Заключение
Клъстерният анализ е много удобен инструмент за идентифициране на пазарни сегменти. Особено в нашата епоха на високи технологии, когато машините идват на помощ на човек, такъв трудоемък процес става буквално въпрос на секунди.
Формирането на сегменти зависи от наличните данни и не се определя предварително.
Променливите, които формират основата за клъстериране, трябва да бъдат избрани въз основа на опита от предишни проучвания, теоретичната основа, хипотезите, които се тестват, и по преценка на изследователя. Освен това трябва да се избере подходяща мярка за разстояние (прилика). Характеристика на йерархичното групиране е развитието на йерархична или дървовидна структура. Методите за йерархично клъстериране могат да бъдат агломеративни или разделени. Агломеративните методи включват: метод на единична връзка, метод на пълна връзка и метод на средна връзка. Широко използван дисперсионен метод е методът на Бард. Методите за нейерархично клъстериране често се наричат методи на k-средни стойности. Тези методи включват метод на последователен праг, метод на паралелен праг и оптимизиращо разпределение. Йерархичните и нейерархичните методи могат да се използват заедно. Изборът на метод за групиране и изборът на мярка за разстояние са взаимосвързани.
Решението за броя на клъстерите се взема по теоретични и практически причини. При йерархично групиране важен критерий за вземане на решение относно броя на клъстерите са разстоянията, на които клъстерите се сливат. Относителните размери на клъстерите трябва да бъдат такива, че да има смисъл да се запази даден клъстер, вместо да се слее с други. Клъстерите се интерпретират от гледна точка на клъстерни центроиди. Клъстерите често се интерпретират чрез профилирането им чрез променливи, които не са били основата за клъстериране. Надеждността и валидността на решенията за клъстериране се оценяват по различни начини.
клъстерна йерархична агломеративна дендограма
Референции
1. Василиев V.I. и др.. Статистически анализ на обекти от произволен характер. Въведение в статистиката на качеството, М.: ИКАР, 2004г.
2. Икономически и статистически анализ / Изд. Иленкова С.Д. -М .: УНТИТ, 2002.
3. Парсаданов Г.А. Прогнозиране и планиране на социално-икономическата система на страната, М.: ЮНИТИ, 2001
Публикувано на Allbest.ru
Линейно програмиране. Геометрична интерпретация и графичен метод за решаване на ЗЛП. Симплексен метод за решаване на PLP. Метод на изкуствена основа. Алгоритъм на метода на минималния елемент. Алгоритъм на потенциалния метод. Метод на Гомори. Алгоритъм на метода на Фогел.
резюме, добавено на 02/03/2009
Графичен метод за решаване на задачата за оптимизация на производствените процеси. Приложение на симплекс алгоритъм за решаване на икономически оптимизиран проблем за управление на производството. Метод на динамично програмиране за избор на оптимален профил на пътя.
тест, добавен на 15.10.2010 г
Аналитични и числени методи за неограничена оптимизация. Метод на елиминиране и метод на умножителя на Лагранж (LMM). Методът на Ойлер е класически метод за решаване на проблеми с неограничена оптимизация. Класическа задача за ограничена оптимизация. За практическото значение на MML.
резюме, добавено на 17.11.2010 г
Основни методи за решаване на задачи от линейното програмиране. Графичен метод, симплекс метод. Двоен проблем, потенциален метод. Моделиране и характеристики на решаване на транспортен проблем с помощта на потенциалния метод с помощта на възможностите на Microsoft Excel.
тест, добавен на 14.03.2014 г
Видове проявление на количествените връзки между признаците. Дефиниции на функционални и корелационни връзки. Практическото значение на установяването, посоката и силата на корелацията. Метод на квадратите (метод на Пиърсън), рангов метод (метод на Спирман).
презентация, добавена на 19.04.2015 г
Геометричен метод за решаване на стандартни проблеми с линейно програмиране с две променливи. Универсален метод за решаване на каноничния проблем. Основната идея на симплексния метод, изпълнение с помощта на пример. Таблична реализация на прост симплекс метод.
резюме, добавено на 15.06.2010 г
Очевидно първоначално решение за поддръжка. Симплексен метод с естествена основа. Графичен метод за решаване на задачи по линейно програмиране. Двоен проблем, оптималното му решение. Матрица на съотношението на разходите. Пълна схема на междуотрасловия баланс.
тест, добавен на 30.04.2009 г
Цели на пазарното сегментиране в маркетинговите дейности. Същността на клъстерния анализ, основните етапи на неговото прилагане. Избор на метод за измерване на разстояние или мярка за подобие. Йерархични и нейерархични методи за групиране. Оценяване на надеждността и валидността.
доклад, добавен на 11/02/2009
Мета на клъстерния анализ: разбиране, алгоритъм, дизайн. Основни характеристики на процедурата на McKean. Графика на средните стойности за три клъстера. Метод на К-методи, предимства и недостатъци на изследването. Разбиране за алгоритмите за клъстериране на мрежи (базирани на мрежи).
резюме, добавено на 27.05.2013 г
Математическа теория за вземане на оптимални решения. Табличен симплекс метод. Формулиране и решаване на задача с двойно линейно програмиране. Математически модел на транспортната задача. Анализ на осъществимостта на производството в предприятието.
Марийски държавен технически университет
Отдел RTiMBS
Клъстерен анализ
Указания за лабораторна работа
Йошкар-Ола
200 8
Въведение
Теоретична част
Проблем с клъстерния анализ
Методи за клъстерен анализ
Алгоритми за групиране
Брой клъстери
Дендограми
Практическа част
Пример
Примерно решение в програматаSPSS 11.0
Примерно решение в програматаSTATISTICA
Лабораторно задание
Заключение
Референции
Приложение
Въведение
Голяма група задачи за анализ на данни, базирани на използването на статистически методи, са така наречените проблеми с класификацията. Има три подполета на класификационната теория: дискриминация (дискриминантен анализ), групиране (клъстерен анализ) и групиране.
Основната цел на клъстерния анализ е да раздели набора от изследвани обекти и характеристики на групи или клъстери, които са хомогенни в подходящия смисъл. Това означава, че проблемът с класифицирането на данните и идентифицирането на съответната структура в тях се решава. Методите за клъстерен анализ могат да се използват в най-различни случаи, дори в случаите, когато говорим за просто групиране, при което всичко се свежда до формирането на групи на базата на количествено сходство.
Голямото предимство на клъстерния анализ е, че ви позволява да разделяте обекти не според един параметър, а според цял набор от характеристики. В допълнение, клъстерният анализ, за разлика от повечето математически и статистически методи, не налага никакви ограничения върху типа на разглежданите обекти и позволява да се разглеждат различни първоначални данни от почти произволен характер.
Клъстерният анализ ви позволява да разгледате доста голямо количество информация и драматично да намалите и компресирате големи количества информация, което ги прави компактни и визуални.
Клъстерният анализ може да се използва итеративно. В този случай изследването се провежда до постигане на необходимите резултати. Освен това всеки цикъл тук може да предостави информация, която може значително да промени посоката и подходите към по-нататъшното приложение на клъстерния анализ. Този процес може да бъде представен като система за обратна връзка.
Различните приложения на клъстерния анализ могат да бъдат сведени до четири основни задачи:
разработване на типология или класификация;
изследване на полезни концептуални схеми за групиране на обекти;
генериране на хипотези въз основа на изследване на данни;
тестване на хипотеза или изследване, за да се определи дали типовете (групите), идентифицирани по един или друг начин, действително присъстват в наличните данни.
Техниките за групиране се използват в голямо разнообразие от области. Hartigan (1975) дава отличен преглед на много публикувани изследвания, съдържащи резултати, получени чрез методите на клъстерен анализ. Например, в областта на медицината групирането на заболявания, лечение на заболявания или симптоми на заболявания води до широко използвани таксономии. В областта на психиатрията правилното диагностициране на клъстери от симптоми като параноя, шизофрения и др. е от решаващо значение за успешната терапия.
Недостатъци на клъстерния анализ:
Много методи за клъстерен анализ са доста прости процедури, които като правило нямат достатъчно статистическа обосновка
Методите за клъстерен анализ са разработени за много научни дисциплини, поради което носят отпечатъка на спецификата на тези дисциплини.
Различните клъстерни методи могат и действително генерират различни решения за едни и същи данни.
Целта на клъстерния анализ е да се намерят съществуващи структури. В същото време неговият ефект е да въведе структура в анализираните данни, т.е. методите за групиране са необходими за откриване на структура в данните, която не е лесно да се намери чрез визуална проверка или с помощта на експерти.
Университет: VZFEI
Година и град: Москва 2008 г
1. Въведение. Концепцията за метода на клъстерния анализ.
2. Описание на методологията за прилагане на клъстерен анализ. Тестови пример за решаване на проблем.
4. Списък на използваната литература
Клъстерният анализ е набор от методи, които правят възможно класифицирането на многомерни наблюдения, всяко от които се описва от набор от характеристики (параметри) X1, X2,…, Xk.
Целта на клъстерния анализ е формирането на групи от подобни обекти, които обикновено се наричат клъстери (клас, таксон, кондензация).
Клъстерният анализ е една от областите на статистическите изследвания. Тя заема особено важно място в онези клонове на науката, които са свързани с изучаването на масови явления и процеси. Необходимостта от разработване на методи за клъстерен анализ и тяхното използване е продиктувано от факта, че те спомагат за изграждането на научно обосновани класификации и идентифициране на вътрешните връзки между единиците на наблюдаваната съвкупност. В допълнение, методите за клъстерен анализ могат да се използват за компресиране на информация, което е важен фактор в контекста на постоянно нарастване и сложност на потоците от статистически данни.
Методите за клъстерен анализ ви позволяват да разрешите следните проблеми:
Извършване на класификация на обекти, като се вземат предвид характеристики, които отразяват същността и природата на обектите. Решаването на такъв проблем, като правило, води до задълбочаване на знанията за съвкупността от класифицирани обекти;
Проверка на направените предположения за наличието на някаква структура в изследваното множество от обекти, т.е. търсене на съществуваща структура;
Изграждане на нови класификации за слабо проучени явления, когато е необходимо да се установи наличието на връзки в една популация и да се опита да се въведе структура в нея (1, стр. 85-86).
2. Описание на методологията за прилагане на клъстерен анализ. Тестови пример за решаване на проблем.
Клъстерният анализ позволява n обекта, характеризиращи се с k характеристики, да бъдат разделени на хомогенни групи (клъстери). Хомогенността на обектите се определя от разстоянието p(xi xj), където xi = (xi1, …., xik) и xj = (xj1,…, xjk) са вектори, съставени от стойностите на k характеристики на i съответно -ти и j-ти обекти.
За обекти, характеризиращи се с числени характеристики, разстоянието се определя по следната формула:
p(xi , xj) = √ ∑(x1m-xjm) 2 (1)*
Обектите се считат за хомогенни, ако p(xi xj)< p предельного.
Графично представяне на съюза може да се получи с помощта на клъстерно дърво на съюза - дендрограма. (2. Глава 39).
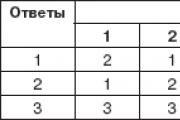
Тестов случай (пример 92).
|
Обем на продажбите |
|||||
Нека класифицираме тези обекти по принципа на „най-близкия съсед“. Нека намерим разстоянията между обектите по формула (1)*. Да попълним таблицата.
Нека обясним как се попълва таблицата.
В пресечната точка на ред i и колона j се посочва разстоянието p(xi xj) (резултатът се закръгля до втория знак след десетичната запетая).
Например в пресечната точка на ред 1 и колона 3 е посочено разстоянието p(x1, x3) = √(1-6) 2 +(9-8) 2 ≈ 5.10, а в пресечната точка на ред 3 и колона 5 разстоянието p(x3, x5) = √ (6-12) 2 + (8-7) 2 ≈ 6,08. Тъй като p(xi, xj) = p(xj,xi), долната част на таблицата не е необходимо да се попълва.
Нека приложим принципа на „най-близкия съсед”. В таблицата намираме най-малкото от разстоянията (ако има няколко от тях, изберете някое от тях). Това е p 1,2 ≈ p 4,5 = 2,24. Нека p min = p 4,5 = 2,24. След това можем да комбинираме обекти 4 и 5 в една група, т.е. комбинираната колона 4 и 5 ще има най-малкото от съответните числа в колони 4 и 5 на оригиналната таблица на разстоянията. Правим същото с редове 4 и 5. Получаваме нова таблица.
В получената таблица намираме най-малкото от разстоянията (ако има няколко от тях, изберете някое от тях): p min = p 1.2 = 2.24. След това можем да комбинираме обекти 1,2,3 в една група, т.е. комбинираната колона 1,2,3 ще съдържа най-малкия от съответните номера на колони 1 и 2 и 3 от предишната таблица на разстоянията. Правим същото с редове 1, 2 и 3. Получаваме нова таблица.
Имаме два клъстера: (1,2,3) и (4,5).
3. Решаване на задачи за теста.
Задача 85.
Условия:Пет производствени съоръжения се характеризират с две характеристики: обем на продажбите и средна годишна цена на дълготрайните производствени активи.
|
Обем на продажбите |
|||||
|
Средногодишна стойност на дълготрайните активи |
Решение:Нека намерим разстоянията между обектите по формула (1)* (закръглена до два знака след десетичната запетая):
р 1,1 = √ (2-2) 2 + (2-2) 2 = 0
р 1,2 = √ (2-5) 2 + (7-9) 2 ≈ 3,61
р 1,3 = √ (2-7) 2 + (7-10) 2 ≈ 5,83
p 2,2 = √ (5-5) 2 + (9-9) 2 =0
р 2,3 = √ (5-7) 2 + (9-10) 2 ≈ 2,24
p 3,4 = √ (7-12) 2 + (10-8) 2 ≈5,39
p 3,5 = √ (7-13) 2 + (10-5) 2 ≈ 7,81
p 4,5 = √ (12-13) 2 + (8-5) 2 ≈ 3,16
Въз основа на резултатите от изчислението попълнете таблицата:
Нека приложим принципа на „най-близкия съсед”. За да направите това, намираме най-малкото от разстоянията в таблицата (ако има няколко такива разстояния, изберете някое от тях). Това е p 2,3=2,24. Нека p min = p 2.3 = 2.24, тогава можем да обединим обектите от колони “2” и “3”, както и да обединим редовете от обекти “2” и “3”. В новата таблица въвеждаме най-малките стойности от оригиналната таблица в комбинираните групи.
В новата таблица намираме най-малкото от разстоянията (ако има няколко от тях, изберете някое от тях). Това е p 4,5 = 3,16. Нека p min = p 4.5 = 3.16, тогава можем да обединим обектите от колони “4” и “5”, както и да обединим редовете от обекти “4” и “5”. В новата таблица въвеждаме най-малките стойности от оригиналната таблица в комбинираните групи.
В новата таблица намираме най-малкото от разстоянията (ако има няколко от тях, изберете някое от тях). Това е p 1, 2 и 3 = 3,61. Нека p min = p 1, 2 и 3 = 3,61, тогава можем да обединим колонни обекти "1" и "2 и 3", а също и да обединим редове. В новата таблица въвеждаме най-малките стойности от оригиналната таблица в комбинираните групи.
Получаваме два клъстера: (1,2,3) и (4,5).
Дендрограмата показва реда на избор на елементи и съответните минимални разстояния p min.
отговор:В резултат на клъстерен анализ, използващ принципа на „най-близкия съсед“, бяха формирани 2 клъстера от подобни обекти: (1,2,3) и (4,5).
Задача 211.
Условия:Пет производствени съоръжения се характеризират с две характеристики: обем на продажбите и средна годишна цена на дълготрайните активи.
|
Обем на продажбите |
|||||
|
Средногодишна стойност на дълготрайните активи |
Класифицирайте тези обекти, като използвате принципа на „най-близкия съсед“.
Решение:За да разрешим проблема, представяме данните в оригиналната таблица. Да определим разстоянията между обектите. Нека класифицираме обектите според принципа на „най-близкия съсед“. Представяме резултатите под формата на дендрограма.
|
Обем на продажбите |
|||||
|
Средногодишна стойност на дълготрайните активи |
Използвайки формула (1)* намираме разстоянията между обектите:
p 1.1 =0, p 1.2 =6, p 1.3 =8.60, p 1.4 =6.32, p 1.5 =6.71, p 2.2 =0, p 2.3 =7.07, p 2.4 =2, p 2.5 =3.32, p 3.3 = 0, p 3.4 =5.10, p 3.5 =4.12, p 4.4 =0, p 4.5 =1, p 5.5 =0.
Представяме резултатите в таблицата:
Най-малката стойност на разстоянията в таблицата е p 4.5=1. Нека p min = p 4.5 = 1, тогава можем да обединим обектите от колони “4” и “5”, както и да обединим редовете от обекти “4” и “5”. В новата таблица въвеждаме най-малките стойности от оригиналната таблица в комбинираните групи.
Най-малката стойност на разстоянията в новата таблица е p 2, 4 и 5=2. Нека p min = p 2, 4 и 5=2, тогава можем да обединим обектите на колоните "4 и 5" и "3", както и да обединим редовете на обектите "4 и 5" и "3". В новата таблица въвеждаме най-малките стойности от таблицата в комбинираните групи.
Най-малката стойност на разстоянията в новата таблица е p 3,4,5=2. Нека p min = p 3,4,5=2, тогава можем да обединим обектите на колоните “3,4,5” и “2”, както и да обединим редовете на обектите “3,4,5” и „2“. В новата таблица въвеждаме най-малките стойности от таблицата в комбинираните групи.
| или влезте в сайта. |
1 . Адрианов А.Ю., Линзен Л., Клъстерите като инструмент за развитие на нестопански организации // www.dis.ru.
2. Алимбаев А.А., Притворова Т.П., Таубаев А.А. Формиране и развитие на клъстери в условията на индустриално и иновативно развитие на Република Казахстан // www.liter.kz
3. Аналитична бележка за юли-август 2006 г. на Териториалния орган на Федералната държавна статистическа служба за Астраханска област
4. Блудова С.Н. Регионалните клъстери като начин за управление на външноикономическия комплекс на региона // www.ncstu.ru
5. Бородатов А.В., Кожевникова В.Д. Инициатива за създаване на туристически и развлекателен клъстер Севастопол // Бизнес партньор. - 2004. - № 10. - С. 33-37.
6. Буряк А.П., Воропов А.Г. Клъстерен анализ - основа за управление на конкурентоспособността на макро ниво // Маркетинг. - 2003. - № 1. - С. 34-40.
7. Давидов А.Р., Лялкина Г.Б. Нови форми на организиране на иновационния процес. Международен опит // www.dis.ru
8. Дранев Ю.Н. Клъстерен подход към икономическото развитие на териториите. - М.: Издателство "Сканрус", 2003. - 195 с.
9. Засимова Л.С. Темпове на растеж на производството на хранително-вкусовата промишленост в района на Астрахан // www.volgainform.ru
10. Капустин А.Н. Инвестиции в туризма: качество срещу количество // www. astrakhan.net
11. Кутин В.М. Териториална икономическа групировка (класификация) на руските региони: социално-географски аспект // Сигурност на Евразия. - 2003. - № 1. - С. 21-28.
12. Лий С. Клъстери - нови форми на организиране на иновационния процес // www.naukakaz.kz.
13. Lozinsky S., Prazdnichnykh A. Конкурентоспособност и индустриални клъстери: нов дневен ред за руския бизнес и правителство // Светът на строителната индустрия. - 2003. - № 2. - С. 32-41.
14. Мартинов Л.М. Темпове на растеж на производството на хранително-вкусовата промишленост в района на Астрахан // www.caspy.net
15. Мелникова С.В. Основата за просперитета на астраханския туризъм е специална екологична политика // Туризмът в Русия. - 2006. - № 8. - С. 31-35.
16. Мигранян А.А. Теоретични аспекти на формирането на конкурентни клъстери // www.dis.ru.
17. Михеев Ю.В., Хасаев Г.Р. Клъстери чрез партньорство към бъдещето // www.ptpu.ru.
18. Николаев М.В. Клъстерна концентрация на ефективна интеграция на регионите в глобалната икономика // www.subcontract.ru
19. Перкина М.В. Хотелиерският бизнес взема звезди от небето // Астраханские ведомости. - 2006. - № 19. - С. 3.
20. Портър M.E. Състезание: пер. от английски: Уч. село - М .: Издателска къща Уилямс, 2000. - 495 с.
21. Портър М. Международен конкурс. - М.: Международен. отношения, 1993.- 869 с.
22. Постановление на правителството на Астраханската област № 368-P от 2510.2006 г. относно секторната целева програма „Развитие на туризма в Астраханската област за 2007 г.“.
23. Програма за социално-икономическото развитие на Астраханска област, като се вземе предвид удвояването на брутния регионален продукт за 2005-2007 г.
24. Свиридов А.П. Екотуризмът може да спаси Астраханската област // www.volga-astrakhan.ru
25. Симачев Ю.В. Клъстерирането като начин за гарантиране на конкурентоспособността на региона // www.clusters-net.ru
26. Соколенко С.И. От клъстерни изследвания до развитие на мрежови търговски и производствени структури // Руски икономически журнал. - 2004. - № 6. - С. 10-15.
27. Соколенко S.I. Развитие на туристически и рекреационни клъстери: регионална инициатива на Украйна // Регион. - 2004. - № 2. - С. 19-22.
28. Спанкулова Л.С. Проблеми на развитието на клъстерната икономика на индустрията на регионално ниво // AlPari. - 2004. - № 2. - С. 16-
29. Статистически годишник на социално-икономическото развитие на Астраханска област 2004, 2005 / Териториален орган на Федералната държавна статистическа служба за Астраханска област
30. Стеблякова Л.П. Проблеми на създаването и развитието на икономически клъстери: опит на чужди страни // Сборници на Карагандинския университет по бизнес, управление и право. - 2005. - № 2. - С. 22-29.
31. Стеблякова Л.П., Вечкинзова Е.А. Формиране на клъстери за конкурентоспособност в централен Казахстан // www.liter.kz
32. Стратегически план за развитие на общинското образувание "Град Астрахан" за 2005 - 2010 г.
33. Стратегия за развитие на туризма в Астраханската област в средносрочен и дългосрочен план, 2005 г.
34. Филипов П. Клъстери за конкурентоспособност // Експерт. - 2003.- № 43. - С. 10-15.
35. Цихан Т.В. Клъстерната теория на икономическото развитие // Теория и практика на управление. - 2003. - № 5. - С. 22-25.
36 . Зарибяване A.A. Механизми за повишаване на конкурентоспособността на регионалните икономики // www.subcontract.ru
37. Шеховцова Л.С. Клъстерът като модерен инструмент за повишаване на конкурентоспособността в региона // www.clusters-net.ru
38. www.astrahanpages.com
39. www.astrasocial.ru
40. www. astrgorod.ru
41. www. astrobl.ru
42. www. asttour.ru
43. www.economy.astrobl.ru

Елена Шишкина Презентация „Денят на Земята“ Презентация „Денят на Земята“. Цел: формиране на идеи, че планетата...

Интересувате се от свободна позиция, публикувана на уебсайт за работа. Какво да правя след това? Специалисти по търсене на работа...

Професионалните умения и личните качества са задължителна точка при попълване на кандидатура или за всяка свободна позиция. В...

Един тест може да отговори на сложен въпрос - кой съм бил в минал живот, какво съм правил и какъв живот съм водил. По-долу са...
Скали: стилове на вземане на управленски решения: laissez-faire, маргинален, прилагащ, авторитарен,...
Когато развивате бизнес, е много трудно да избегнете неадекватно увеличаване на персонала. Колкото по-голямо е предприятието, толкова повече...

Години на раждане: 1927, 1959, 1991, 2023, 2055 Цвят: Синьо-зелен Символика на знака: Безсмъртие, дълголетие,...
За успешно въвеждане на документа за уволнение ще проверим настройките на програмата 1C 8.3, за да избегнем грешки в...

Кайдзен (改善 kaizen) е японска философия или практика, която се фокусира върху непрекъснатото...

Слайд 2 ЦЕЛ НА УРОКА Образователна: Да научи учениците да самостоятелно (с помощта на учебни и технологични...

Имало едно време един свещеник с дебело чело. Отишъл попът на чаршията да разгледа някаква стока. Балда идва към него, но той не е...

През октомври 2008 г., след премиерата в мрежата на продължението на конспиративния филм на Питър Джоузеф Zeitgeist...

Всеки знае, че без трудов стаж е невъзможно да се намери добро работно място. Ако го нямате, не го пропускайте...

Основният начин за автоматизиране на процесите на механична обработка на детайли за дребномащабно и индивидуално производство...

Интересувате се от свободна позиция, публикувана на уебсайт за работа. Какво да правя след това? Специалисти по търсене...

Професионалните умения и личните качества са задължителна точка при попълване на формуляр за кандидатстване или за...